


TikTok Live Show + AI’s Regulatory Future: EU vs. China
“The AI industry is hitting the gas in terms of progress and deployment — and I think that governments around the world need to hit the gas in terms of thinking about it in a regulatory context.”
We’re picking up our conversation with Matt Sheehan and Hadrien Pouget from last week. In this post we discuss:
Why it’s maddeningly difficult to construct AI standards that fully account for the uncertain, probabilistic nature of models;
The EU’s and China’s AI regulatory trailblazing, how their approaches differ from each other, and what the US can learn from each;
The nexus between values and technical standards, and how that poses to bifurcate China’s and the West’s AI regulations;
Why Chinese chatbot engineers are so stressed out!
Also, the long-awaited TikTok hearing has finally arrived!
On Thursday, March 23, at 10 a.m. Eastern, TikTok CEO Shou Zi Chew will appear before the House Energy and Commerce Committee to testify about “TikTok’s consumer privacy and data security practices, how the platform affects children, and its relationship with the Chinese Communist Party.”
I’ll be doing a ChinaTalk livestream recording — for paid subscribers only — right after the hearing, along with the great Kevin Xu of Interconnected.
Come listen in at 12:30 ET! Link to the livestream is below the paywall at the end of the post:


The EU ‘Ruffles Some Feathers’
Jordan Schneider: So Hadrien, Europe is freaking out. What are they trying to do to hold back the floodgates, and why are you skeptical that what they’re trying to achieve may not be realistic?
Hadrien Pouget: The EU is trying to limit the kind of AI systems that can hit the EU market, because the European is just an agreement between lots of countries to coordinate their markets, so that’s the lever it has to pull.
And the way it pulls that lever is by, very high-level, separating AI into different applications, and then those applications into “prohibited,” “high-risk,” and “low- to medium-risk” — and then essentially laying out these requirements, called “essential requirements,” that all the systems must meet before they can be put on the EU market.
These essential requirements are intended to be very high-level: “Make sure that that your data has appropriate statistical qualities” — a lot of those kinds of vague words. And then what’s going to happen: they’re relying on standards that will be more technical and more grounded to bring a bit more precision to these essential requirements.
Currently they’re working on the AI Act — which is going to have these essential requirements — and they have just started working on technical standards that are going to support the AI Act.
Jordan Schneider: So right now we have some principles which seem fine. But you argue in a recent piece in Lawfare that AI standards are uniquely hard to set. Why is that?
Hadrien Pouget: I think they’re going to be difficult for all kinds of reasons. One is the need to deal with a lot of uncertainty in terms of evaluating these systems — and I think this uncertainty comes from two main parts:
First of all, the harms from AI can be diffuse and complex — it’s not just physical safety: it can be bias; it can be harder harms to society as a whole, shaping its information environment. The AI Act isn’t going to get at all of those because it’s based on certain applications, but it’s going to have to start to contend with them. And so suddenly, answers to questions like, “In terms of accuracy or robustness, what is a sufficiently representative dataset?” start to be very contextual; it’s complicated to make some kind of unifying framework to get at that.
And then on the other hand, there’s also technical uncertainty. Here I’m thinking of neural networks — systems that are very complex, of which we have a poor understanding, and which can fail and behave in unintuitive ways.
It’s therefore hard right now to just take one of these systems and confidently say how it’s going to behave — which is what these standards are trying to get at: they’re trying to make a list of metrics such that we can confidently say this system will be fine.
So I think the uncertainty from both of these parts — in terms of evaluating a system and the harms it’s going on the technical side — means that it’s going to be hard to make standards that universally lay out a set of metrics or a line that you need to pass to be safe or good enough.
Jordan Schneider: Let’s bring this down to an example: we have ChatGPT, which, if you just ask it right now very directly to tell you QAnon conspiracy theories, it probably won’t. But over the past two months, you’ve seen people come up with very creative ways to have ChatGPT do things that the creators did not intend — by imagining something, or pretending it’s a play, or telling it you’re in “safety testing mode.”
As a regulator, I can’t imagine how you could say, “If anyone ever takes a screenshot of your AI doing something that we don’t approve of, we’re going to fine you $100,00; if it took them ten tries, then we’re going to fine you only $1,000.” Because given the nature of the black box of these models — which is not going to be solved anytime soon — it seems very difficult to imagine some regulatory framework where there isn’t a tradeoff between a product’s innovative capacity and safety concerns.
Hadrien Pouget: Exactly. When you end up in this kind of situation where you’re uncertain about whether or not you should approve the model — no matter what you try to do with ChatGPT, someone is probably going to manage to find a way around it — what should standards say?
I think a key question is, “When do we consider that we don’t have enough information to approve them?” Because I can see standards being almost a checkbox exercise: “As long as you haven’t found any problems doing X, Y, and Z, then it’s fine.” But I think there’s a chance that we just don’t have metrics that are comprehensive enough — and as a result, you’re going to end up with situations where you just don’t have enough information.
So then other regulatory pieces are going to have to come in — things like the threat of liability, where you can, for example, call expert witnesses who can attest to whether you took a reasonable amount of risk.
Matt Sheehan: The way that I tend to think about it: a lot of standards that we’re used to — for either digital systems or physical systems — are describing a mechanistic process. Take the TCP (Transmission Control Protocol) — you know that if you send a packet to x address, you’re going to get y response, and you can essentially describe the entire process. If the machines themselves are not broken, it’s going to produce a predictable result.
AI is fundamentally operating over a probabilistic space. It’s forming a million different intricate connections based on datasets that are not the same each time. And there’s not a reliable way to say what output it’s going to give for any given input.
The classic example: if you take a picture and you say, “Recognize this as a stop sign,” and then you alter just a handful of pixels in a strategic way, suddenly it thinks the stop sign is a cow or something like that. They don’t have a common-sense framework; there’s not a mechanistic relationship that can differentiate between them.
So that’s how I think about the difficulty of setting AI standards. You’re not describing the interlocking of two pieces that are always going to operate the same way. You’re trying to set bounds around a probabilistic process that might fail in a totally weird way that you didn’t anticipate.
Hadrien Pouget: There are medical standards where you’re dealing with something that’s equivalently complicated — for example, the effect of a drug on a body can vary hugely depending on the person, depending on what other medications they’re taking, depending on all kinds of circumstances. What you end up with is some encoded information about the best thing to do in each situation. But then you also have something like the FDA, a regulator which takes a close look at each drug and decides whether or not to pass them. And you also have a lot of information that isn’t encoded in standards, because best practices change a lot, and all these decisions are very contextual.
So when you have to figure out, for example, in court whether someone adhered to best practices, you end up calling in experts to give their testimony and help set a reasonable standard. I think it would be a shame if you had standards that were bad — because then all of a sudden, as a medical professional you could prescribe drugs in situations that didn’t make sense and then refer to standards: “Well, I was just following this globally accepted ‘best practice.’”
Jordan Schneider: Can you talk a little bit about the political economy of these standards? What is driving the current EU approach?
Hadrien Pouget: The current EU approach is just their approach to product regulation in general: they write a regulation, have the technical details sorted out in technical standards, and then have a liability angle as a backstop. And if you read the AI Act, it creates a lot of institutional infrastructure for how to enforce the requirements.
The world in general has a pretty strong culture around standards, which are supposed to be voluntary, consensus-based agreements, ideally coordinated internationally. And the EU is ruffling some feathers to be honest — in that it’s making standards here that are a bit more legally powerful than you would normally have; and it’s also willing to go against, for example, standards that are made at the international level.
And there is right now a real question: “What can the world agree on for AI standards, given that a lot of these technical decisions have values embedded in them?” And so we have seen this space get more politicized over the past few years.
Jordan Schneider: Do you have a theory on how you think it’s going to shake out?
Hadrien Pouget: I think the EU is probably going to stand their ground and make standards their way. They are going to defer to international standards to the extent they can — but as of this moment the international standards haven’t progressed that far, and the EU has a deadline, so it needs to start getting this all done anyways.
I think at the international level, we’re going to create standards. The value of those standards right now isn’t clear to me. We’ll have to see how much they end up getting into the meat of what is considered good enough versus merely making lists of possible metrics.
Jordan Schneider: So let’s walk through your bull and bear cases of AI standards at a national and international level — whether they are useful for the planet.
Hadrien Pouget: The worst possible scenario is that we make standards that give us too much confidence in these systems by using a limited set of metrics, evaluations, or specific specifications.
The best-case scenario is that standards encode what we know without being overconfident — and they make clear the situations in which we don’t have enough information to make informed decisions yet.

China’s Algorithm Registry
Jordan Schneider: So Matt, China is also doing its own version of algorithmic regulation. What’s the backstory there?
Matt Sheehan: For a long time, China — like the rest of the world — was saying a lot of things at a very high level about AI ethics, forming committees, and participating in venues like the UN. But starting from around the end of 2020, they have actually gotten very practical, nuts-and-bolts in terms of passing regulations that will meaningfully constrain algorithms in the way that are deployed.
The two highlights so far: a binding regulation on recommendation algorithms, and a binding regulation on what they call “deep synthesis,” which is basically generative AI initially starting from deep fakes.
And for a long time, I wasn’t that interested in the high-level, abstract conversation about this stuff — but as it’s gotten more real, we have seen China emerge as one of the biggest experiments that we have going in terms of, “How can regulators and governments get their minds or hands around algorithms and constrain them in a meaningful way, or at least increase transparency in a meaningful way?”
So I’m spending a lot of time looking at the nitty-gritty of what China is doing on this front, and then contrasting it to the EU: whereas the EU has this one big horizontal regulation to rule them all in the AI Act, China is taking a more opportunistic or vertical approach. Here, vertical means you pick an application or an issue area, and you tackle it one at a time — as opposed to trying to come up with one all-encompassing regulation.
It’s an interesting moment for people in the US: we basically get to watch these two experiments play out — one big-tent regulation in the EU, and a bunch of targeted regulations in China — and see which approach ends up being more tractable.
Jordan Schneider: You recently wrote a piece with Sharon Du about the requests for information that the Chinese government is asking of firms. What does that tell you about how at least one corner of the bureaucracy is, from an AI regulatory perspective, thinking about what matters and what doesn’t?
Matt Sheehan: We focused on China’s Algorithm Registry. The full Chinese name is 算法备案系统 — technically it translates as “algorithm filing system.” I’ll call it “registry” here.
So this was created by their first algorithmic regulation, which was the one on recommendation engines — and then they carried over this registry into deep-fake regulations as well. They’re basically saying, “If the algorithm that you (as a company or as a developer) have deployed in the world falls within these regulatory frameworks, then you need to submit an algorithm filing to us.
On first brush, it was very unclear what this meant. One extreme interpretation: does this mean they need to hand over the entire code and whole datasets? Is the Chinese government essentially getting 100% transparency and control of these algorithms? The other extreme interpretation is that they just need to fill out forms where they say, “It’s a deep-learning algorithm that recommends content, and it tries to be good and not bad.”
What we found is that, while they did not intend for this information to be public-facing, we were able to find the instruction manual (basically) that the Cyberspace Administration of China had published to give to companies so that they themselves knew how to register their algorithms — and if you zoom in on the instruction manual, it has screenshots of the actual algorithm registration process, and through those screenshots, we can actually gain some insight into what they’re asking.
A lot of this stuff is self-explanatory, like the use case of the algorithm, how to navigate the algorithm, other high-level stuff. But they get into some more interesting requests: they ask them to list all public and private datasets that they use; they ask them to classify their algorithms as to whether or not they use biologically identifying characteristics (like facial data); they ask them to fill out an algorithm security/safety self-assessment test (which I’m still trying to get my hands on).
When we take a step back and look at the sum total of the information they’re gathering, it ends up looking like an interesting foray into forcing algorithmic transparency — but in this case, it’s transparency just toward the government, not toward society at large (for predictable reasons). And it actually ends up looking somewhat comparable to things that have been put forth in US civil society. One of the more popular mechanisms or proposals for algorithmic transparency is something called “model cards” — a concept invented by some researchers in academia, some of them formally at Google. Basically, if you train a machine learning model, you should have to fill out a performance-metrics one-pager on the model, the datasets, how the model performs across, say, different age groups and different ethnicities. You have to fill out information on security concerns or options for misuse.
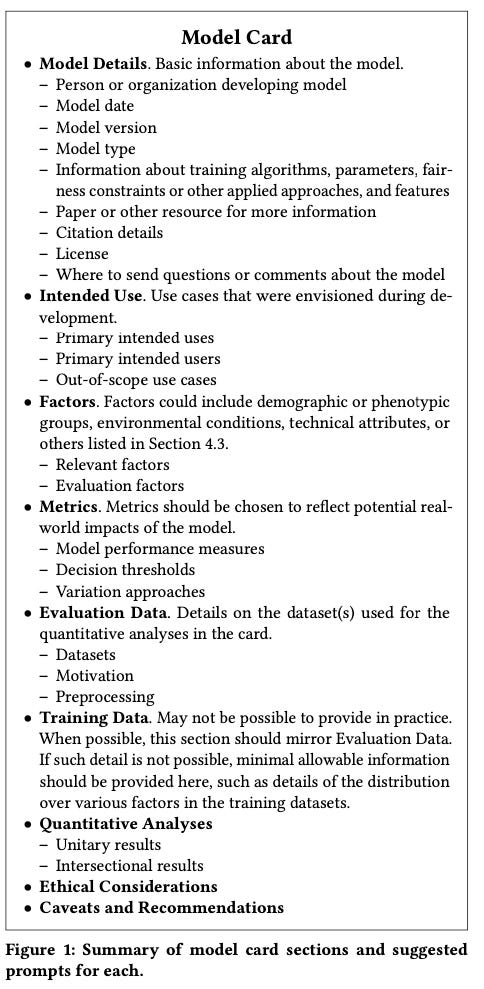
In a lot of ways what the algorithm registry looks like — from the limited window we have into it now — is a form of legally mandated model cards, but where you have to switch the values and the things they care about; obviously the Chinese government’s primary concern is information control (whereas model cards came out of the ML community concerned with fairness and bias and similar issues).
So I see the algorithm registry as an interesting information-gathering process for the Chinese government. When they were trying to start meaningfully constraining stuff like Weibo and social media platforms in China, there was an era of the Chinese internet being the Wild West. But they slowly worked with companies to gain insight into how their systems worked and how they could be censored — and eventually they were able to tighten their grip and effectively control the social media space in China.
The algorithm registry is one potential way that the government is trying to build the intellectual scaffolding for similar regulatory controls on algorithms in China.
Jordan Schneider: It’s interesting thinking about algorithmic regulation and whether the rubber’s going to hit the road faster in the EU or China.
Regarding the ChatGPT-QAnon scenario we discussed earlier — America is just going to be less freaked out about that because we have the First Amendment.
But in China, if I were working at Company A and wanted to ruin Company B’s day, I would get my best prompt engineers to have Company B’s model say some outrageous stuff and post something on Zhihu saying, “Look at all this terrible stuff this company said about the Party.”
So the folks who are probably most stressed out are Chinese engineers building large language models — they don’t know what’s inside their LLMs, but they are certainly going to be blamed if their models end up spitting out content that would not otherwise make it past the Great Firewall.
Matt Sheehan: It’s going to be a huge challenge. Baidu has announced that it’s trying to roll out its own ChatGPT-like product sometime in March — and I would not be surprised if it gets delayed for exactly that reason. Maybe Baidu will take a rigid approach — for instance, the word “Tiananmen” can never appear in any output. But I think it’s going to be much harder to constrain these LLMs if you want to keep them flexible.
Maybe the Chinese versions of these will end up being significantly less flexible with hard-encoded blacklists. In the US, we’re trying to get at some nuance — maybe you can say “Nazi,” but only if you’re saying the right thing about Nazis. Whereas in China, they might just be like, “There’s no right or wrong thing. Just put it on the blacklist. It can never say that word.”
Jordan Schneider: Maybe in 2007 you could get by with just not saying Tiananmen or Falun Gong — but in 2023 in Chinese discourse, the definition of 反华 [Ed. “anti-Chinese”] is constantly expanding.
So even if you could snap your fingers and have your large language model never talk about politics, that still wouldn’t save you — because it would say, for instance, “American movies are better than Chinese movies,” and someone would get really mad at you.
Reflections on the AI Regulatory Enterprise
Matt Sheehan: I think it’s easy to like shoot down any of these regulations as infeasible or unable to meaningfully constrain algorithms. And it is true that we don’t know how to meaningfully constrain an algorithm at this point in time — in the immediate term everything is kind of a one-shot thing.
Subscribe to get the link below to ChinaTalk’s first ever TikTok live show. As a bonus, you’ll also get to read the rest of my conversation with Matt and Hadrien, which includes:
What we can glean from the EU’s and China’s different approaches to AI regulation;
Why it may be tricky for society and rapidly progressing AI to peacefully assimilate to each other;
The philosophical underpinnings for AI regulations.