


AI Compute 101: The Geopolitics of GPUs
“If systems continue becoming that powerful and that capable, we might not actually want them again as a society, as a democratic process; we might not want them to be out there in the wild.”
In the AI triad — data, algorithms, and computing power — how do we make sense of compute’s outsized role?
To discuss, I spoke with Lennart Heim from Epoch and Chris Miller, author of Chip War. We discussed:
What compute is, and why it’s important;
The challenges of innovating on the chip level (as opposed to, say, the algorithmic level);
Allocation strategies for computing power;
The feasibility of chip smuggling, in light of the recent chip export controls;
The uneasy alliance between technology and morality;
Pertinent parallels between energy-sector and chip regulations.
Enjoy!
Jordan Schneider: To make sense of the hardware that’s powering the explosion in AI capabilities, I have on Lennart Heim today. He’s a researcher at the Centre for the Governance of AI. He’s also the author of a fantastic AI compute syllabus primer, which I just spent the past few weeks obsessed with — and now I feel like a smart person all of a sudden. Co-hosting with me today is Chris Miller, author of the recent FT Business Book of the Year, Chip War.
A Tour of Compute
Jordan Schneider: What is compute?
Lennart Heim: Usually when I talk about compute, I mean something about computing infrastructure, computing resources. It’s this vague thing which we as a civilization have been built over the last hundred years — from processors, to memory, to more specialized stuff like GPUs in general, to those clunky things which are sometimes in your pocket, but also those things which fill up data centers. Computing infrastructure is a good term to go for to describe compute.
Jordan Schneider: So there’s this concept of an AI triad, which we can say was popularized by Ben Buchanan, now on the NSC: the idea that data, algorithms, and compute are the three inputs that you need in order to have a flourishing product, as well as — one level of abstraction up — a national economic AI innovation system. Is the relationship of relative importance between those three already baked in today?

Lennart Heim: Oh yeah, I think the debate has not settled on this one yet. I also like the term AI production function, which is just basically asking yourself, “Well, we have AI systems which get created, and what are the inputs into the systems?” And then you have people who don’t have computer science backgrounds who try to simplify that — and as you just said, compute algorithms and data is one way of going about it. And now the question is, “What is the most important of those?” I guess it depends who you ask.
I think one thing we can say over time is that compute plays an important role, and somebody should be focusing on it, even if it’s just one-third of the production function. In particular, if we look at one subfield of AI — in particular, machine learning — compute plays a major role. And lastly, compute is a necessary component: we cannot do AI stuff without processors, without compute.
Jordan Schneider: Sure. So what is the range of futures in which you need giant server farms with millions if not billions of these chips? Or is there a world in which the algorithms and data get so good that compute actually isn’t going to be a limiting factor on how good AI can get?
Lennart Heim: It’s important that we think about the computer requirements of AI systems — to look at the lifecycle, where we are with systems. You have AI stuff running on your smartphone right now — be it Siri, be it Google Assistant — and they’re even trying to push it further, so that it completely runs on your smartphone and not on Google’s server, for privacy-preserving reasons.
The difference is that those systems have been trained. We show them millions of hours of speech examples to be trained on; this usually gets done in data centers — and then we can talk about warehouses of compute.
But yes, there is a strong interest in actually deploying systems on your smartphone. We have this for voice systems. But if you look at newer systems — you mentioned ChatGPT: well, this runs somewhere in Microsoft Azure, in big data centers, because it needs a lot of compute, as it has somewhere around a million users per day. If you have a million users per day, and you actually want to serve them all, with quick latency, then you run it on data centers, which tend to be more efficient.
Chris Miller: So what’s the right way to think about the productivity of the different aspects of the AI triad — compute, data, algorithms? We have the concept of Moore’s Law in terms of computing power. So how would you measure productivity of algorithms, or productivity of data changing over time?
Lennart Heim: There’s actually some pretty good research on this. We wrote a paper where we looked at all the cutting-edge machine learning systems and asked, “How much compute, how many floating-point operations do we need for training those systems?” And we tried to plot this and see what happened there.
We saw that it doubled every six months over the last ten years. That’s huge, right? Because if we compare this to Moore’s Law, it’s been doubling only every two years. If we then try to find the same multiplier for algorithm efficiency or data, it gets way harder.
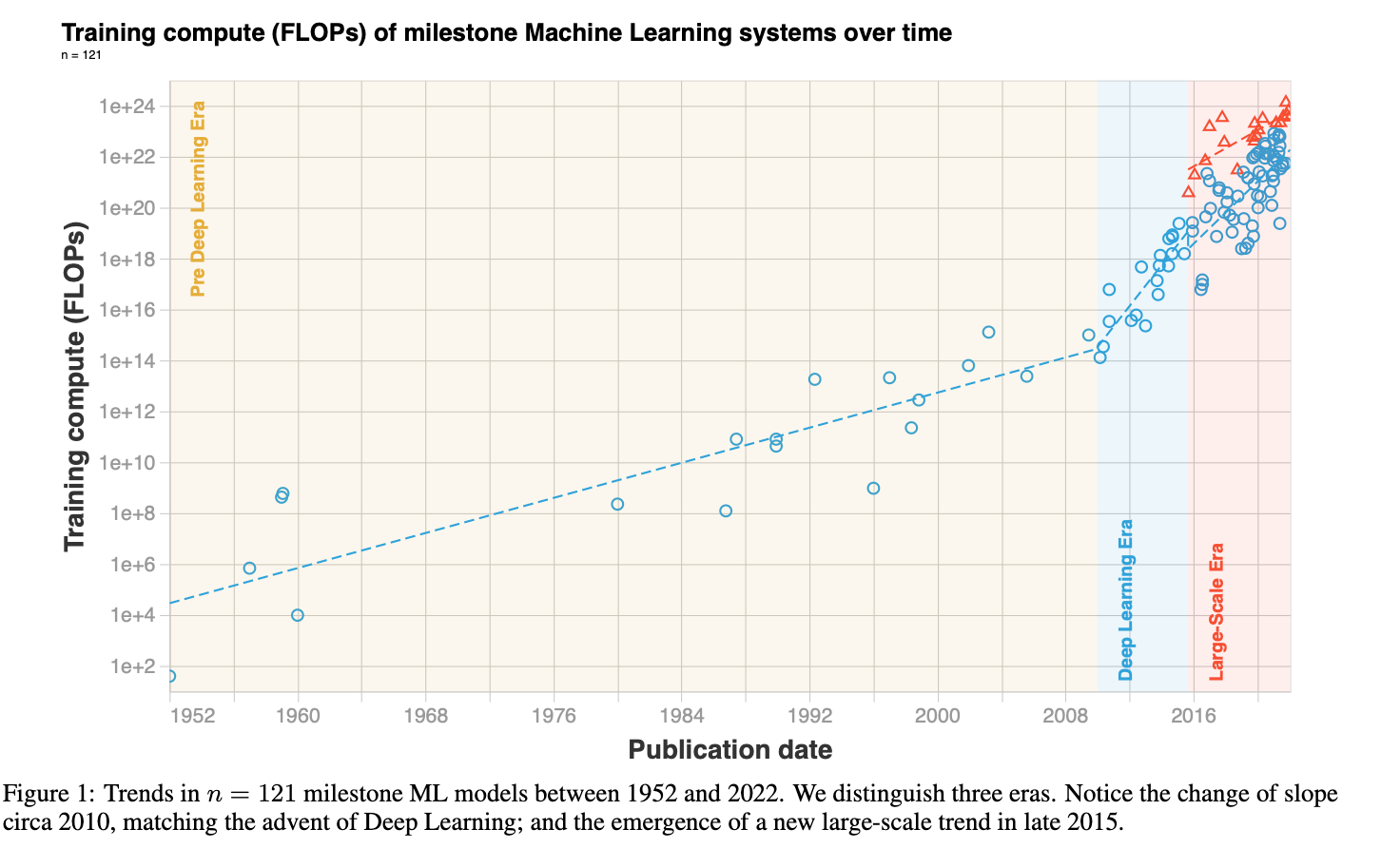
I’m also at an organization called Epoch, where we also look at data trends, where we try to investigate how much data is doubling — and the same for algorithmic efficiency.
One way to think about efficiency is to ask, “Do we get the same performance for less compute?” Then we met algorithmic efficiency. And that’s also just a way of measuring it. There’s a blog post from OpenAI called “AI and Efficiency,” and my colleague Tamay recently published a paper where he took a look at an image and tried to figure this out. And they found out that the progress of algorithm efficiency has been as important (at least for image recognition) as in compute — which is interesting, because a bunch of people have always been saying, “Well, it’s only compute, it’s only scaling that you need.” But actually, while we scale those systems, we’ve also been making better algorithms, making more use of compute, and we also get more data sets — all of those things are scaling at the same time.
But I think it’s really important to get more research going to actually figure this out.
Chris Miller: What are the inputs to more efficient algorithms? Obviously you need smart people designing smart algorithms — but beyond that: if the inputs to more advanced semiconductors are better machine tools and better processes, how do you think about the inputs to better algorithms?
Lennart Heim: I think naively you can just say, “Talent.” The question is, “How much do you push them for it?” I mean, there’s this term in software engineering called bloatware: our software became more bloaty and less efficient over time because processors became so good. If your software is not fast enough right now, you just wait two years and it’s going to be fine, because we have Moore’s Law pushing across the edge.
So if Moore’s Law goes down, there might be more of a push toward having more efficient systems.
On the other side, we see it already right now. If you spend millions on training runs and make a system that uses ten percent less compute, that saves you a lot of money — which is an interest of every business.
Jordan Schneider: Well, it doesn’t save you that much money, though. What’s interesting to me is the balance between open and closed in improving algorithms. OpenAI has a great team, they have dozens of engineers — and I’m sure they are some of the smartest folks out there — but that’s very different from what you saw happen to Stable Diffusion when it was released: the entire internet was working through improvements to the model, and then fast forward a few months and you can run it on an iPhone.
I think there’s a real power in having algorithmic innovations be open-sourced in a way where it will be really interesting to see if the monetary edge of the OpenAIs and DeepMinds of the world not needing to worry about spending $1 to 2 million on their training run, as opposed to competing against some open-source model — models which may be a little more cash-constrained but will have far more brains on the project trying to tweak what goes into the training and inference.
Lennart Heim: That seems roughly right. But I think it’s still important to differentiate it from the training of Stable Diffusion. To my understanding, I don’t know how many people were on the core team of Stable Diffusion; I’m not even sure how much of this whole stake is open-source — I guess most of it. But if you actually read up in the comments, you’ll see it’s only ten or so people who actually deploy it.
Apple just released something to make Stable Diffusion run locally on MacBook M-1 Airs. And it’s pretty exciting, trying to run this more efficiently. But again, it needs orders of magnitude less compute. You cannot train those systems on your laptop. You would probably wait until the heat death of the universe before this gets done.
Jordan Schneider: So, are we running out of compute, Lennart?
Lennart Heim: Tough question. Probably not. I think the question is, “Do we want to stop spending on compute?” What we’ve seen so far, if you look at how much compute we use to train ML systems — this has been doubling every six months. And then according to an analysis from 2020, it was doubling every three months — so it leveled a bit off.
I think we also remember from covid: exponential growth is a pretty big deal, and it cannot continue forever. The reason why we could double every single time is because we had something like Moore’s Law happening, so we get more compute, more FLOPs [floating-point operations], every two years. But if something doubles only every two years, and then everything doubles every six months, you can’t enable it with more spending only. And this is what we’ve seen with spending way more money and way more compute infrastructure to train those systems.
And there was a report by our folks from CSET (Center for Security and Emerging Technology): at some point we hit limits where training systems costs, say, one percent of US GDP. Are we willing to spend one percent of US GDP on training just one model right now? I don’t think so.
Jordan Schneider: Yeah, but what if it’s just the sickest model?
Lennart Heim: Maybe we’ll spend one percent, maybe ten percent — but then I would start to become a bit skeptical on whether we would actually do it…
Jordan Schneider: I was being facetious — but there is a world in which whatever this is turns into a Manhattan Project and you end up needing tens of billions of dollars of government support that the private sector isn’t going to get. So maybe, Lennart, talk us through the world in which that is the thing that nations need to do to compete.
Chris Miller: And I would just add: $1 billion isn’t that much for big tech firms. That’s a totally viable amount of spending.
Lennart Heim: Right, maybe $1 billion is on the horizon. I once estimated the cost of PaLM (Pathways Language Model, a language model from Google), if they trained this on their own cloud resources: it’s roughly $9 to 14 million — and that’s just paying for the training. You have just one shot to get it right. You still need to deploy it, which costs a lot of money. And you still need to play around with it and develop it.
Jordan Schneider: It’s interesting, because I saw a lot of charts in my reading, and there were several studies you linked to that started to get into diminishing returns — when you increased beyond the $10, 15, 20 million threshold.
But I think there’s definitely a world in which whatever new algorithm can be twenty times as good as the last one — but only if you give it a billion dollars’ worth of compute. And I think, now that the importance and potential of these models have been generated, it would not be particularly difficult to convince VCs or some CEO of a public company that this is something their firm needs to take a big bet on.
I did think it was really funny that, apparently, Google called an emergency board meeting the week after GPT-3 was launched, and I wouldn’t be shocked if Sundar Pichai was like, “Don’t worry — we’re going to pour in billions of dollars to blow them out of the water.”
Lennart Heim: Going back to this AI triad and the production function — what we still forget is that it’s not only compute. You cannot do AI models by only making them ten million times bigger. You still need an algorithm. The neat thing we’ve been doing over the years is naively making models bigger, hoping one day they’ll turn out better.
But we also needed this more data. If you want to scale up a model a hundred times, you also need 500 times the amount of data. And this might actually also be a limitation, because we cannot use any data. Do you want to train your model on Reddit? Probably not. It might actually be the case where you would spend a little amount of money, but you don’t have enough data to actually train those kinds of models. You’re running out of data, literally, and then it really depends on the domain — if it’s language, or image, or those kinds of things.
Smaller Transistors vs. Better Algorithms
Chris Miller: Okay, so question: drilling into the economics of this — you can spend more on designing smarter algorithms, you can spend more on compute, and then on the compute side, you can spend more brute forcing and getting more transistors. But, you can also spend on designing chips so that they’re perfectly attuned to the algorithm that you’re trying to run. So talk us through that dynamic; it’s more complex the more you dig into it, in terms of the optimization cost.
Lennart Heim: We’ve talked about chips and compute, but I think the more interesting dynamic is, “What kind of chips are out there?” There’s a spectrum around chips — chips which are really general, and chips which are really specialized.
As you move further along the spectrum: the more specialized you get, and the less general you are — but also, the more efficient you get. And what we’ve seen with AI: at some point people figured, “Well, we can use those CPUs because it turns out training our AI algorithms is just lots of metrics and applications.” Sometimes people say it’s embarrassingly parallel. And then they started using those GPUs and became way more efficient.
This is a good example of where you were using chips which didn’t have more transistors or smaller transistors — or maybe even a bigger feature node than your CPU. But it turns out it’s ten to a hundred times more efficient because you have a specialized architecture there.
So, we should not forget that we have this physical inspiration — we have Moore’s Law, more transistors, more cores, more of all those things. But actually, we can move across the spectrum where we have architectural innovation.
And this is also partially what kicked off the merchants of machine learning. Many people say that the deep-learning area started with AlexNet. Deep learning, big networks mean we need lots of compute; what they started doing there is using those graphics processing units for their AI workloads. And lucky Nvidia is caught up on this, and now they have chips which are not used for gaming anymore — they have dedicated AI chips used for training those big models. That is how you can innovate without putting more chips on stuff — you innovate with architecture innovation. This is the algorithmic innovation on the compute level.
Chris Miller: Is it cheaper or more efficient to innovate on the chip level or to innovate on the algorithmic level? What’s the right way to think about that tradeoff?
Lennart Heim: I can’t say from the top of my head — it’s pretty hard. What we’ve seen on the chip level is that ideas are getting harder to find. We need to spend exponentially more money to get smaller transistors. But it’s turned out pretty good: the companies who did that have become really rich from it.
What we’ve seen historically: we’ve done both at the same time. Ideally, I have architecture innovation and the transistors get smaller — then I have a double win. And this is to some degree what Nvidia has been doing: they continue using smaller nodes — while TSMC, SML, and all the others continue innovating. At the same time, Nvidia, who doesn’t make the transistors smaller, just came up with new architectures which are more specialized toward the workloads and machine learning training. And then you have a multiplication effect: you’ve got a better architecture, and you’ve got better chips.
Maybe one of those is going to stop in the future. In the same way it’s hard to make resistors smaller, it’s hard to find architectural innovations. We’ve been trying this for the last ten years.
Chris Miller: On the data aspect — you mentioned the potential risk that we run out of relevant data. On the one hand, there’s an infinite amount of information in the world, but not all of it is in data form that you can easily plug in as ones and zeros. But, what’s the right way to think about running out of data? It seems like an implausible challenge to face, given that our main difficulty right now is making sense of all the data that exists in the world. How would you characterize the challenge, and what’s the first kind of data limitation we might actually bump up against?
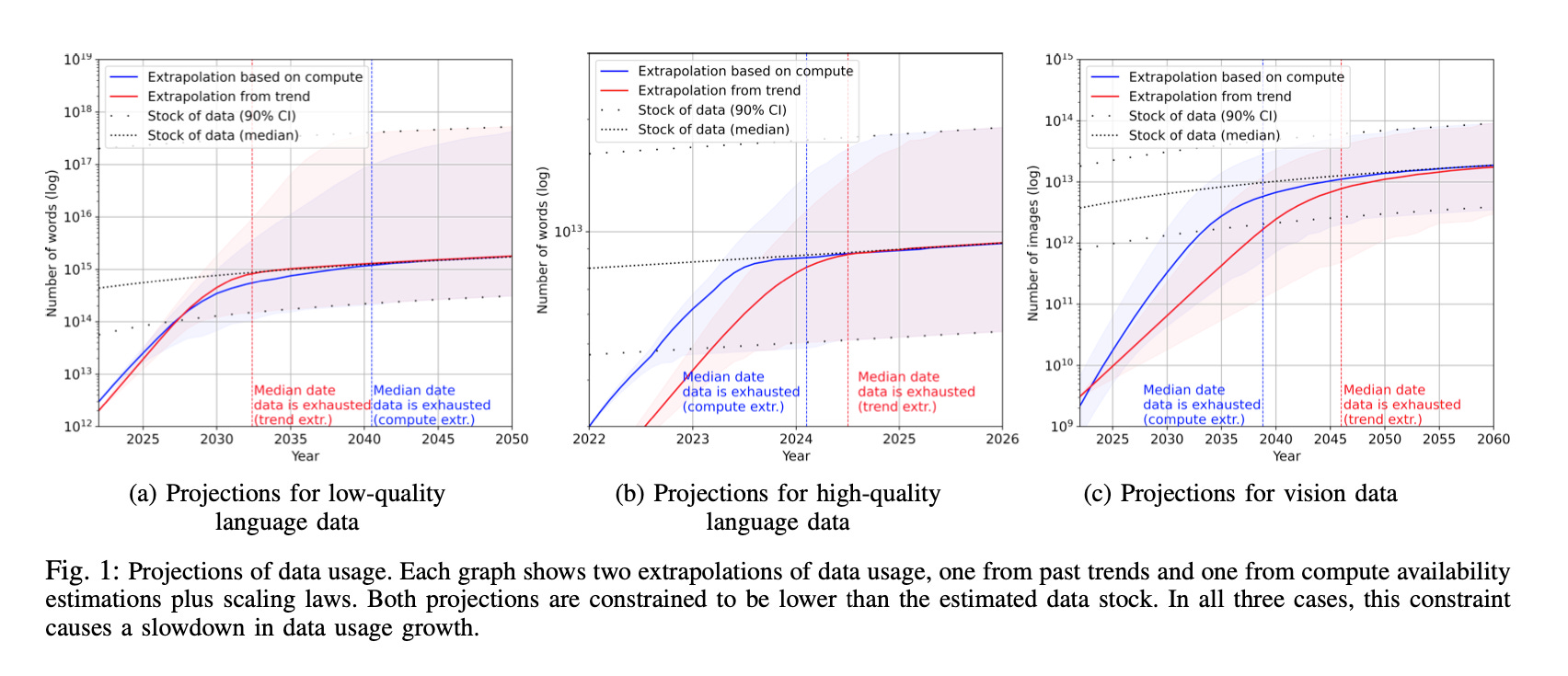
Lennart Heim: I think the first limitation is high-quality data. There’s not an infinite number of books out there in the world — there’s a limit to it; and we feed surprisingly many books into those systems. GPT-3 has read many, many, many books, more than any of us combined could ever read within a lifetime. But there’s still a limit to it. So what you want to have is more data efficiency.
I haven’t read 10 million books, but sometimes I can reason as well as ChatGPT (maybe, I don’t know: I haven’t played around with that much). But there’s better data efficiency in humans, compared to some system where we need to feed in lots of images and it needs to see a cat 10,000 times before it understands what a cat is. I think we as humans are doing a better job there.
But this idea of high-quality data being out — there’s actually a bottleneck. If I only trained kids on 4Chan … let’s just say, something really terrible would turn out, something not very smart; it would be pretty awful at reasoning and arguing.
We recently wrote a paper which asked, “Are we going to run out of data?” and tried to make some estimates of how much data is out there, how much data we actually produce to get a handle on this.
Precisely How Should We Allocate Compute?
Jordan Schneider: What are the arguments for and against spending federal money to give university researchers and less-well-funded startups access to this compute?
Lennart Heim: You’re pointing to a big discussion in the US right now, which is called the National AI Research Resource (NAIRR). The NAIRR tries to give academics, and also startups and small businesses, access to compute.
What are the arguments in favor? I think I just described it — participating at the frontier of machine learning research. If you think about creating systems, you need a lot of compute. And it’s already debatable: is this the frontier of ML research? There’s a reason why Google and all the others create systems — because systems are the things which you eventually make money from.
Academic incentives might be different: they might play around just try to understand how the systems actually work. But on the other side, you might want to play around with cutting-edge systems to see how they work. So for them to participate at the frontier of AI research, they need access to compute.
The problem is: how do we give them access to compute? Do you want to set up another high-performance cluster next to the university? Do you want to give them money and then buy it from Amazon Web Service or Microsoft Azure? Or does everybody get another computer under their desk? I think those are the questions we still need to figure out — what is the best way of actually giving them access to compute, so they actually are using it?
Jordan Schneider: I think the answer is you give them AWS credits. Whatever federal version of AWS is going to be bad, and giving everyone an A-100 on their desk doesn’t solve the problem. Am I missing something?
Lennart Heim: Maybe. I agree in that for many people, a federal project is a big worry. We have high-performance clusters, right? And there’s a reason why people sometimes like to go to AWS or Microsoft Azure — because they just work well: you pay what you get for, and they’re efficient.
On the other side, as I just said, if I just give you the credits now to train the system, it’s pretty hard. You still need to run those systems — and it has become its own science to deploy those large training runs, because it’s not a single A-100 under your desk. We’re talking about thousands of chips. This is distributed computing. This is its own academic discipline — to make this efficient. If you don’t make it efficient, if you don’t care about optimization, you’ll be ten times worse than you could be — which means you’ll spend ten times more money, which means you spend $10 million instead of $1 million. So there’s still this aspect where you need operational support for deploying those models.
Chris Miller: Yeah. So what are the counterarguments to providing this type of service?
Lennart Heim: Let’s just assume they’re successful: if we give them enough compute, then we’re going to be creating powerful AI systems. But there is this barrier we just talked about: those systems get even more powerful.
That’s an interesting discussion which started a couple of months ago — it’s around the open-sourcing of those systems. Stable Diffusion made a lot of noise asking for the democratization of AI models. It’s a complex matter. I’m coming from an engineering discipline, and I’ve been a huge fan of open source my whole lifetime. But now I’m advocating a bit against it: those systems in the future will be ever more powerful, ever more capable — and we should really think carefully about deploying them into the real world, because they can do real harm via misuse.
That’s part of the reason why my colleague Markus Anderljung and I have recently been advocating to the NAIRR: maybe it should consider something we call structured access, instead of open sourcing; give a way for people to access the systems, but in a safe and secure way. An example of this would be via an API where researchers can interface with it, but the model is not out there in the wild where everybody can just deploy it on their systems. I think the misuse of future ML systems is exactly the thing we need to look out for.
I’m not saying it’s a big danger right now, but I think we are getting some early hints at this with Stable Diffusion, where it might be misused. But in the future, we should consider it even more — if systems continue becoming that powerful and that capable, we might not actually want them again as a society, as a democratic process; we might not want them to be out there in the wild.
Chris Miller: Well, I guess that brings up the question of governance — who makes those decisions, and how are those decisions made? Is that a corporate decision? Are there new institutions set up? Do governments decide?
Lennart Heim: I think this is exactly the discussion which the NAIRR should be having. I think what the answer is not: that the researcher who trained the model should decide.
You might be arguing, this is anti-democratic, right? Because it’s not the population who is deciding. So we would need a process of how we best go about it and how we balance the benefits and the downsides of those models. Structured access is one way you might want to go about it — it brings the benefits but tries to minimize the downside risks. Again, I think it’s a really important thing to look out for — if the systems become stronger and stronger over time.
Become a paid subscriber today to read 4,000 more words of discussion — things we talk about include:
Why compute is an obvious target to bottleneck, relative to data and algorithms;
How cloud computing makes compute a non-rival good;
Lennart’s take on why cloud providers are ultimately the only entities which can assume responsibility for how their technology is used;
What AI policymakers can learn from regulatory models applied previously in other domains, like nuclear energy;
How sublinear scaling will challenge Moore’s Law in the near future.