


AI’s Regulatory Future
“If the US stops collaborating with China, it doesn’t mean they won’t get access to the best, leading-edge results. Those results live on the internet for everyone in the world to access.”
With AI on the verge of transforming the world, how are regulators across the globe approaching the challenges the technology might pose? To talk AI policy, algorithmic regulation, and US-China research collaboration, I invited Matt Sheehan and Hadrien Pouget, both of Carnegie, to the show.
In part one, we discuss:
What US-China AI collaboration looks like today, and how it has evolved since the early 2000s;
CS publication culture’s tendency toward open-sourcing, and whether AI will incline researchers — and regulators — to keep more of their code under the hood;
Who is really winning the AI race?

US-China AI — We Go Way Back
Jordan Schneider: Matt, you recently came out with a paper exploring all of the dimensions of US-China AI research collaboration. Why don’t you first give us a brief snapshot of just how prevalent US-China AI research collaboration is, and then bring us back to the beginning.
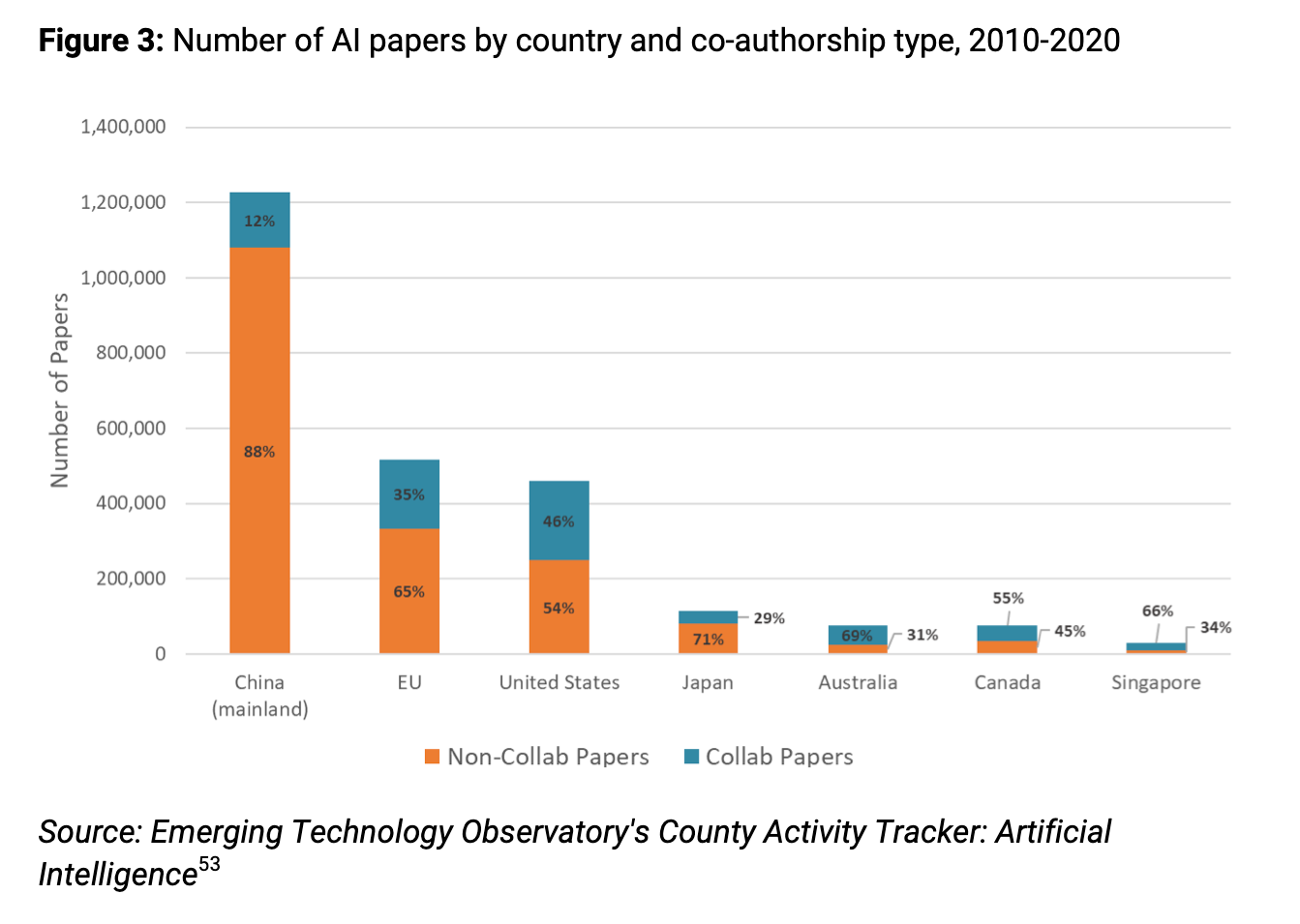
Matt Sheehan: When it comes to collaborative research — jointly publishing AI papers, working together in AI labs — first off, the US and China are number one and number two in terms of total AI publications and elite AI publications; and they’re also by far the largest pair of collaborators. So US-China collaborations greatly outnumber US-UK, China-Australia, any other combination you can come up with — and I think that’s almost by a factor of five relative to the next highest collaborative pair. (If you really want to dig into that, I highly recommend the Country Activity Tracker, which is a project by CSET, that lets you dig into the data; we put some of that in our report.)
So basically, you have the US and China as the global leaders in terms of output of top-tier AI research. You have them as the number-one pair of collaborators — but then you throw a million different geopolitical, ethical, logistical, covid-induced problems at that relationship, and you’ve got a very fraught situation. So what we were doing in the paper was trying to unpack the nature of not just the US but democracies in general collaborating with China on AI research — to give us a state of play and then a set of (hopefully actionable) recommendations in terms of how we should think about this and how researchers, institutions, governments should make decisions when it comes to working with China and AI research.
In terms of the US and China leading AI research: the US obviously has a long-standing lead in terms of global scientific output across not every discipline, but the vast majority of disciplines; and this has been going on for a very long time. China’s rise is much more recent, and one of the things that I try to do in the paper is to give a potted history of twenty-five years of Chinese AI development — so, going back into roughly the late 1990s, before the deep-learning revolution of the present day, before AI was a business model that was on everybody’s mind, and before China was thought of as a technological power in any capacity. When we go back that far, I think it changed the way that the two countries interacted in AI.
One of the first big interactions between the two of them was when Microsoft set up its computer science research lab in Beijing. It’s called Microsoft Research Asia. It was set up in the late 1990s. The founding director was Dr. Kai-Fu Lee. It was established by Bill Gates in part to draw on talent from there, and also to secure Microsoft’s place in the Chinese market.
I often look at the founding of Microsoft Research Asia as an interesting snapshot of how different things are today. Back then, the US government and US society were still excited about integrating China into the global economy: the Berlin Wall had fallen, we were still on this “China is eventually going to turn into us, one way or another” track, and mostly we were going to profit from it in a great way. China was seen as so far behind in most forms of technology that it wasn’t at all seen as problematic that Microsoft would open a cutting-edge research lab there.
That lab turned out to be a very important accelerator in the development of China’s early AI ecosystem. Within a span of just a few years, it turned into what the MIT Technology Review in 2004 called “the world’s hottest computer science lab.” And it became a training ground where lots of the future founders, CTOs, and technology presidents of China’s leading internet platforms — and then AI companies — would come out of. And it was also producing cutting-edge research on its own.
Starting somewhere between 2008 to 2012, we had the early rumblings of deep learning eventually bursting onto the stage with its great performance, breaking records at ImageNet, etc. And in that period of time, what I think is important is that China was developing and fostering its own internet giants. When we think about AI competitiveness, I think a big part of it’s just, “Do you have giant internet companies that hire tons of engineers that have tons of data and tons and users?” I think an overlooked ingredient in China rising as an AI power is just the fact that it was able to foster its own homegrown internet giants.
As deep learning was taking off globally, China’s rise as a technological power was still overlooked by Silicon Valley and by the US government, I’d say, up all the way through 2017; they didn’t really take it seriously as a technology competitor. But suddenly in 2017: Trump administration, national AI plan — and the pendulum of assessments of China’s technology capabilities, and specifically AI capabilities, swing from one end to the other. It goes from thinking, “China is a technological backwater, and they’ll never catch up because they don’t have free speech or free markets,” all the way to the other side of, “Look: Xi Jinping says they are going to be the world’s number-one AI leader in 2030, and that means they absolutely will be the world’s number-one AI leader in 2030.”
At the same time that the US government was waking up to Chinese technology prowess, they were also waking up to how deep and rich the research ties are between the two countries — for instance, the fact there are so many Chinese students populating and leading computer science labs in the US, leading tech companies, etc.
So the US government had this rather kneejerk reaction: “China is a technology power. They have all these ties. That means that the ties are directly what led to it becoming a technology power. Therefore we need to cut those ties, and then they will fall off and will never be able to keep up with us.”
Jordan Schneider: So to recap, we have: a world in which Hu Jintao meets Bill Gates at Microsoft and says, “Thank you for making the software that I use to do all my daily business” — all the way to the State Council in 2017 talking about how China needs to be an AI power, and then over the past few years this research (which has been pretty uncontroversial for most of the twenty-first century) all of a sudden getting a lot of unwanted attention from the perspective of these scholars who are publishing all these cross-specific papers.
Computer Science Culture vs. The Billions on the Line
Let’s now go through the different vectors of collaborations. You mentioned joint research and publications, students in the US, and conferences. Another thing I think is really interesting — and which is particularly unique to AI research — is the idea that your innovations are published openly. Do you want to talk a little bit about how that norm has developed in computer science over the past few decades?
Hadrien Pouget: This publication culture around AI grew out of the publication culture of computer science, which was very much about, first of all, conferences (rather than journals): here you would publish in conferences — but you still had this whole peer-review system.
Jordan Schneider: So there’s peer review to get into the conference?
Hadrien Pouget: Exactly — peer review to get into the conference, whether it be a poster or a bigger presentation, you have this peer-review system.
Jordan Schneider: So why do computer scientists publish openly?
Hadrien Pouget: At first in computer science, there was a pretty big culture around conferences where your work gets peer-reviewed — but then by the end it would still, through the conference’s procedures, end up being public; that was always a part of the culture.
What happened next: Cornell made this database called arXiv [Ed. pronounced like “archive”; the χ is the Greek letter “chi”] where people could put what are called “preprints” — that is, before peer review, you would put up prints of your paper as a way to stake that you had gotten this result, that you had had this moment at the cutting-edge, even if by the time you got around to the conference someone else had beaten you.
As a result, that has changed a lot of the culture, because people weren’t waiting to have things peer-reviewed like in many other scientific endeavors. Quite often, people would publish their code on arXiv, and then others would be iterating on it before it ever got peer-reviewed.
So things move a lot faster. There were obviously some replication crises — but overall, it seems that it helped the entire movement move a lot faster. And it was very open; anyone could access any of these.
Matt Sheehan: I think this is really important for understanding the way that knowledge is disseminated in AI. One of the key interventions that we’re trying to make in the paper is disabusing a lot of policymakers, especially American policymakers, of the idea that, “If we just stop collaborating with Chinese researchers, or if we just stop co-authoring papers with them, or stop opening AI labs where we work together — if we just get rid of those connections, then they won’t be able to leach all this great AI research off us; they will fall further behind.”
In reality, machine learning is generally a highly replicable field. With rapid online publication, as soon as a paper is up on arXiv, researchers anywhere in the world who have the base-level skills of coding, compute, and access to data can replicate and build on that result.
So AI has turned into this fast-spinning progress cycle — one that’s not really mediated by conferences and where knowledge is not bound up only in these co-authorship relationships. That should inform the way we think about cutting ties with China and AI research. If we stop collaborating with them, it doesn’t mean they won’t get access to the best, leading-edge results. Those results live on the internet for everyone in the world to access.
Jordan Schneider: But what’s interesting: this dynamic may be changing as the biggest, greatest AI developments are turned into billion-dollar companies, and are not necessarily immediately uploaded to arXiv for cred points.
DeepMind CEO Demis Hassabis recently gave an interview to TIME: “‘We’re getting into an era where we have to start thinking about the freeloaders, or people who are reading but not contributing to that information base,’ [Hassabis] says. ‘And that includes nation states as well.’ He declines to name which states he means—‘it’s pretty obvious, who you might think’—but he suggests that the AI industry’s culture of publishing its findings openly may soon need to end.”
Any thoughts on how AI is transitioning from an interesting thing you do in a lab to something that’s going to have dramatic ramifications for the global economy — and how that transition may impact the publishing culture that we’ve seen develop over the past few decades?
Hadrien Pouget: I think it’s important to note the reason this all was open at first. Part of it is cultural: open science, everyone wants to work together. But the real reason companies were so okay with this culture is that for them it was a way of staking out their reputation; leaders in the field attract a lot of talent, while a lot of the applications weren’t that commercializable.
But now as we’re approaching this point where the cutting edge is looking commercializable — where OpenAI has put ChatGPT out there and been like, “We can make something out of this” — there is this natural tendency to be like, “Okay, now the stuff we’re putting out is actually really valuable, so we’re going to do it a bit more behind closed doors.”
So I see this very much as a kneejerk reaction to the fact that, all of a sudden, stuff that still seemed cutting-edge but that you couldn’t make that much money from — suddenly you can.
Matt Sheehan: I think there is also a huge cultural divide within the AI research community, and it’s split along several lines.
There are people who have been taken the approach of moving toward more closed research — and there are different levels of that. You can be fully closed off — as in, “We’re going to make a product; you can use the product, but we’re not going to tell you anything about what is behind.” Or you can access it through an API — that is, you can write a paper describing what you did, but not give the full code.
And then there’s the other extreme: where you fully release the model, you release the weights of the model (that is, the results of the training run) — and then with a very small amount of data, you can give someone everything they would need to recreate this model, short of the compute; you can give them essentially the model that has already been trained.
Within that, there’s a spectrum — and the question of whether companies should release these is very culturally divisive.
For example: OpenAI was one of the first to say, “We’re going to release GPT-3, but we’re going to first release it in a gated form: we’re going to give access to some people, and then slowly open it up.” Facebook immediately responded, essentially saying, “This is a violation of open science norms and oversight. We’re going to recreate the same thing even bigger, and we’re going to completely open-source it.” Academics and people who are in it more for the pure research are very allergic to the idea of closing this off.
So you have business reasons to close it off — and you also have safety reasons to close it off. There are some people who say, as the models get bigger and more powerful, “We don’t want anyone with a handful of GPUs to be able to recreate this potentially dangerous model.” I think it’s going to be a long time watching this cultural shift play out in different directions.
Jordan Schneider: My bet is that the culture loses — especially when there’s enough money and enough regulatory attention put on this stuff. Sure, it’d be really nice to work at a place that abides by the publishing norms that you’re comfortable with — but what if the other place quadruples your salary? Because that’s how much not abiding by that norm will trickle down to you as an AI researcher.
I think the bull case for this in AI: if the technology ends up playing out where, say, Stable Diffusion — which is biased more toward being open — ends up by dint of it being open sucking in more talent to create things which are cheaper and roughly comparable to what DeepMind and OpenAI can do. But if not, it’s hard to me to envision a future in which the latest and greatest stuff still ends up being open for all.
Am I wrong here?
Hadrien Pouget: I think it’s going to be hard to predict. I’m interested to see what will happen once the gap between the knowledge that’s privately available and publicly available gets bigger. Stable Diffusion was made when that gap was really quite small. And OpenAI, for example, would publish, if not the full model, at least instructions on how to build the model. As that gap gets bigger, it seems possible that we’ll see fewer of these open-source things — unless there are some people who feel really strongly that it should be open-source, and they’re really smart and can keep up on a smaller salary.
Another interesting element: whether private money coming out of this open-source AI research space gives more leverage to the government supplying public money to make certain demands. If governments start to view AI as more strategic, they might start to pull those levers, tighten some of the publication norms, and make that a constraint to receive funding.

Framing the US-China AI Race
Jordan Schneider: One of the big reasons for OSTP (White House Office of Science and Technology) initiatives was to enforce the publication of data when you receive government funding, allowing other scientists to make it more easily replicable.
But when you go from merely doing nice psych studies to a super-powerful dual-use technology that’s going to define the twenty-first century, reverse instincts might come to play when public funding ends up becoming more prominent.
Our conversation continues with:
Hadrien’s take on how access to government funding will affect the publishing culture of AI researchers;
Matt’s take on who is actually winning the AI race;
Why Jordan thinks a US vs. China framing is all but inevitable.