


Ban the H20: Competing in the Inference Age
How inference scaling should change US AI strategy
A guest post by Venkat Somala. He previously served at the Special Competitive Studies Project, the House Select Committee on the Chinese Communist Party, and has held roles in product and data science in industry.
TLDR: U.S. export controls targeting China’s AI capabilities focus primarily on limiting training hardware but overlook the growing importance of inference compute as a key driver of AI innovation. Current restrictions don’t effectively limit China’s access to inference-capable hardware (such as NVIDIA’s H20) and don’t account for China’s strong inference efficiency. While China’s fragmented computing infrastructure has historically been a disadvantage, the shift towards inference-heavy AI paradigms positions their compute ecosystem to be more utilized and valuable. As reasoning models, agentic AI, and automated AI research elevate the role of inference to advancing AI capabilities, the US should urgently strengthen export controls to hinder China’s inference capacity and develop a coherent open-source AI strategy to maintain competitive advantage.
The Export Control Status Quo is Broken
The global AI competition is unfolding along two critical axes: innovation — the development of advanced AI capabilities — and diffusion — deploying and scaling those capabilities. The United States has prioritized outpacing China in AI innovation by focusing on pre-training as the main driver of progress. However, a new paradigm is emerging where inference, not just training, is becoming central to advancing AI capabilities.
This shift has significant implications for U.S. AI policy. Current export controls aim to limit China’s ability to train frontier AI models by restricting access to advanced chips, based on the belief that scaling pre-training is the primary driver of AI progress. By limiting China’s access to compute resources, these controls aimed to slow its AI development.
Yet, these same controls are far less effective at restricting China’s inference capabilities — exposing a critical gap in U.S. strategy. As inference becomes more central to AI innovation, current policies are increasingly misaligned with the realities of AI development. To effectively counter China’s growing inference capabilities, the U.S. must strengthen its export controls.
Inference Compute is a Key Driver of AI Innovation
The AI landscape is evolving beyond the scaling pre-training paradigm that dominated recent years. Emerging solutions are shifting innovation toward a paradigm where inference compute — not just training compute — has become a critical driver of AI progress.
Three interconnected trends are driving the link between inference and AI capabilities:
Reasoning Models
These models require significantly more inference than traditional LLMs, leveraging test-time scaling laws that suggest a link between amount of inference compute and model performance. Inference demand is further driven by a feedback loop that accelerates AI capabilities: reasoning models generate high-quality synthetic data, which enhances base models via supervised fine-tuning (SFT). These stronger models can be adapted into stronger reasoning systems, creating even better synthetic data and fueling continuous capability gains.
Agentic AI
AI agents — systems capable of taking autonomous actions in complex environments to pursue goals — are often powered by reasoning models, which drives up inference demand. Many agents have access to external tools and environments such as code execution environments, databases, and web search, which enhance their capabilities by enabling them to retrieve information, plan, and interact with digital and physical environments.
Some agents continuously learn by interacting with their environment via reinforcement learning. Unlike standard language models that handle one-off queries, agentic AI systems require persistent inference as they continuously interact with external environments, adapt to new information, and make complex, multi-step decisions in real time — significantly increasing overall inference requirements.
Automated AI Research
Automated AI researchers can design new architectures, improve training methods, run experiments, and iterate on findings. Scaling in this paradigm requires both inference compute to power research agents and training compute to execute their proposed experiments. Greater inference capacity allows more of these systems to operate in parallel, expanding both the breadth and depth of AI exploration. This, in turn, enlarges the search space they can navigate and directly increases the rate of AI innovation.
Greater inference also enhances research agents through iterative reasoning, self-play debates, and automated evaluation — capabilities already demonstrated in AI-driven scientific discovery. As these automated systems achieve early breakthroughs, they become better at identifying promising research directions and architectural improvements, potentially setting off a compounding cycle of progress. Thus, even small initial advantages in inference capacity can compound, leading to a significant, potentially decisive, lead in AI capabilities.
In an era of reasoning models, agents, and automated AI research, inference capacity is not just an enabler — it is a primary determinant of the speed and trajectory of AI innovation. This shift has significant implications for the U.S.-China AI competition and underscores the need for stronger U.S. export controls.
China’s Inference Capacity is Key
Current U.S. export controls aim to restrict China’s ability to train frontier AI models but overlook the growing importance of inference and China’s capacity to scale it. As AI development shifts towards inference, China’s position strengthens considerably due to three key factors:
Steady access to inference-viable GPUs
Leading inference efficiency
Compute ecosystem being better suited for inference rather than pre-training
Access to Inference Hardware: The H20 Loophole
Despite U.S. export controls restricting access to cutting-edge AI chips like the H100 and H800, China maintains strong access to inference-capable hardware through several avenues — most notably through Nvidia's H20 GPU.
The H20 represents a significant gap in current export restrictions. Specifically designed to comply with export controls and serve the Chinese market, the H20 is actually superior to the H100 for particular inference workloads. The H20 outperforms the H100 for inference workloads due to its superior memory capacity and bandwidth. It delivers 20% higher peak tokens per second and 25% lower token-to-token latency at low batch sizes—key advantages given that inference performance is driven more by memory bandwidth and batch efficiency than by raw computational power. With 96GB of HBM3 memory and 4.0TB/s memory bandwidth, compared to the H100’s 80GB and 3.4TB/s, the H20 is highly viable for inference, making it a significant gap in current export restrictions.
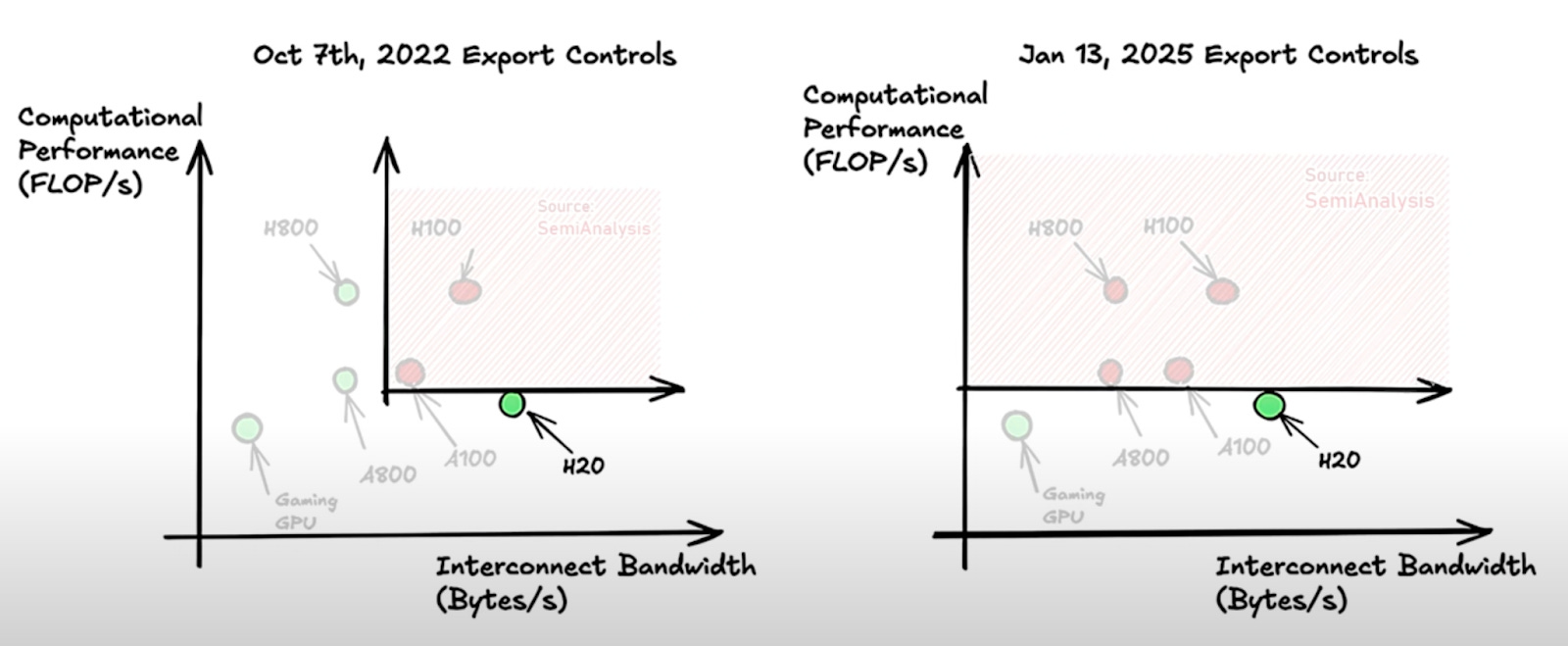
China has been importing large sums of the H20. SemiAnalysis estimates that in 2024 alone, NVIDIA produced over 1 million H20s, most of which likely went to China. Additionally, orders by Chinese companies, including ByteDance and Tencent, for the H20 have spiked following DeepSeek’s model releases.
Access to Inference Hardware: Trailing-Edge GPUs
Trailing-edge GPUs remain surprisingly effective for inference workloads. China retains strong access to trailing-edge GPUs due to large stockpiles of the A100, A800, and H800 in 2022 and 2023. Additionally, Chinese firms, including Huawei, Alibaba and Biren, have also developed indigenous chips. The viability of trailing-edge GPUs for inference suggests that China’s inference capacity is stronger than their volumes of cutting-edge GPUs may suggest.
The effectiveness of older GPUs for inference stems from fundamental differences between inference and training workloads:
Long-Context Inference is Memory-Bound, Not Compute-Bound
Unlike training, inference only runs forward passes, avoiding computationally intensive processes like backpropagation and gradient updates. As a result, inference is significantly less compute-intensive than training.
The real constraint for inference is memory. Inference, particularly long context inference, is currently memory-bound rather than compute-bound due to several factors:
Model Weights & Key-Value (KV) Cache: For transformer-based models, inference requires storing both the model parameters and a key-value (KV) cache. The KV cache stores the past tokens' key-value pairs, allowing the model to retain context and coherence, and grows linearly with the context length. While compute resources are only required to process each newly generated token, memory usage continuously increases as new key-value pairs for each transformer layer are stored in the cache with every additional token generated. Consequently, total memory consumption rises steadily as the context expands, in contrast to compute needs, which remain stable and do not accumulate in the same manner. As a result, inference often becomes memory-constrained before it becomes compute-constrained, particularly for long-context tasks, where the KV cache can exceed the model weights in size.
Autoregressive Bottleneck: Input tokens can be processed in parallel, leveraging the full sequence since it’s known upfront. However, output tokens are generated sequentially, with each new token depending on all the previously generated tokens. This creates a bottleneck during output generation:
Full KV Cache Access: Each generated output token requires accessing the entire KV cache.
Memory Bandwidth Limitation: On long sequences, this repeated full KV cache access for every output token creates a memory bandwidth bottleneck (data transfer rate between memory and processor), which becomes the primary limiting factor.
Constrained Batch Sizes: The size of the KV cache directly limits batch size during output generation. Longer sequences consume more GPU memory, reducing space for batching multiple sequences. This forces smaller batch sizes–the amount of independent user queries that can be processed in parallel–which reduces GPU utilization and restricts inference throughput.
This memory constraint becomes evident when examining FLOP utilization rates. During inference operations, GPUs typically achieve only about 10% FLOP utilization when generating tokens, compared to 30-50% during training. This underutilization occurs because GPUs spend much of their time retrieving and managing the KV cache rather than performing actual computations. The inefficiency grows even more pronounced with newer, more compute-dense chips, where increasingly powerful processing cores sit idle waiting for data to arrive from memory.
The Memory Wall
This inference bottleneck reflects a broader structural limitation in computing hardware. While GPU compute performance has grown exponentially (approximately 3.0x every 2 years), memory bandwidth and capacity have improved at a much slower rate (around 1.6x every 2 years). This growing gap creates a “memory wall” where performance is constrained not by processing speed but by how quickly and how much data the GPU can store and access.
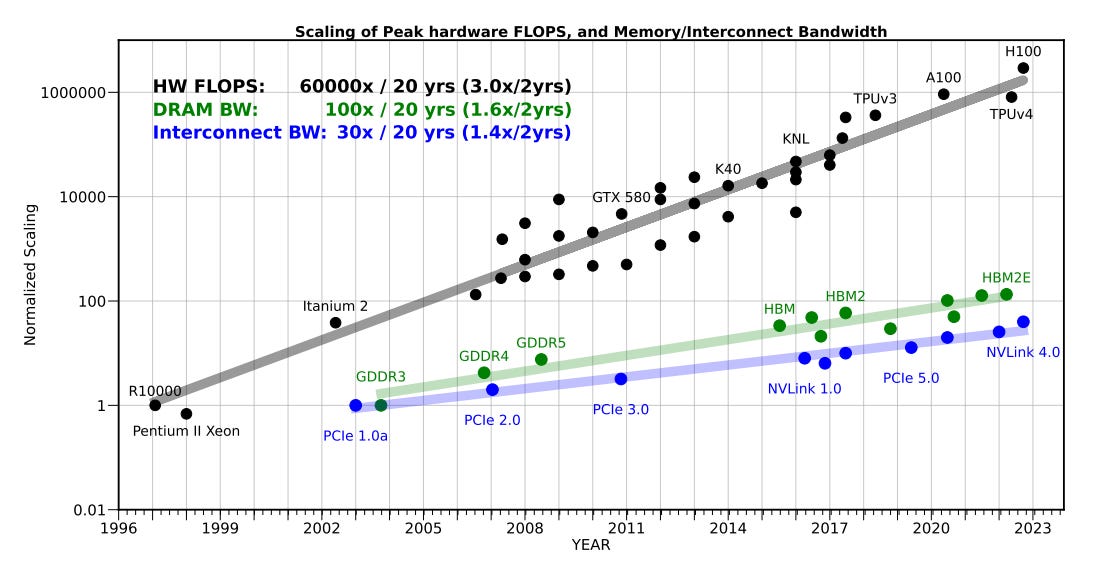
This memory-bound nature of inference has significant implications for hardware viability. While newer GPUs offer exponential improvements in raw computational power (measured in FLOPs), they provide more limited gains in memory capacity and bandwidth — the true bottlenecks for inference workloads.
As a result, inference workloads often cannot fully utilize the computational resources available in cutting-edge GPUs. When memory bandwidth is the primary bottleneck rather than raw compute power, older GPUs remain surprisingly effective for inference tasks. The performance gap between newer and older GPU generations becomes much less significant than their computational performance might suggest.
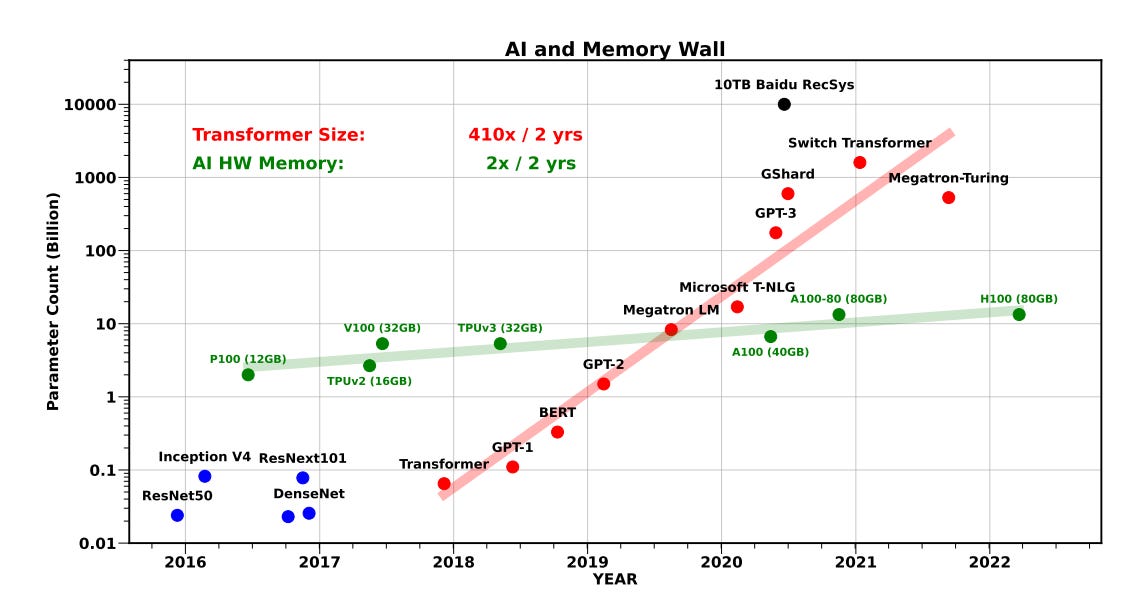
These technical characteristics create a unique hardware dynamic that changes the calculus around AI chips. Trailing-edge GPUs retain viability in an inference-dominated landscape — a generation-old GPU might deliver 60-70% of current-generation inference performance, making it highly viable for most applications. This shifts the cost-effectiveness equation; dollar-for-dollar, older GPUs often provide better inference performance per unit cost than cutting-edge hardware optimized for training workloads. While trailing-edge GPUs quickly become obsolete for training, they remain viable for inference much longer.
Architectural Innovations and Shifting GPU Viability
A single architectural innovation can reshape which GPUs are viable for inference tasks. DeepSeek's Multi-Head Latent Attention (MLA) highlights this dynamic, reducing KV cache requirements by over 90% and fundamentally changing inference bottlenecks.
By shrinking KV cache memory demands, MLA shifts short and medium-context inference tasks from being memory-bound to increasingly compute-bound. Lower memory demands mean GPUs spend less time waiting for data retrieval and more time on actual computation, significantly increasing GPU utilization rates. For China's AI ecosystem, this unlocks substantially more inference throughput from trailing-edge GPUs.
Custom optimizations further amplify these benefits. DeepSeek has demonstrated that Huawei's domestically-produced Ascend 910C can achieve 60% of Nvidia's H100 inference performance through targeted optimizations. This showcases how software and architectural innovations continually reshape the viability and relative strengths of different GPUs for AI workloads.
MLA renders short- and medium-context inference tasks far more efficient by reducing memory bottlenecks, allowing cutting-edge GPUs to fully leverage their computational power. While this widens the performance gap between cutting-edge and trailing-edge GPUs, it also increases China’s overall inference capacity by making older hardware more efficient. Leading-edge GPUs like the H100 will continue to dominate compute-bound workloads, but MLA significantly boosts the total inference power that can be extracted from China’s existing GPU stockpile.
For long-context inference, the hardware calculus shifts again. When context length becomes sufficiently large, tasks remain memory-bound even with MLA, reducing the performance advantage of cutting-edge hardware over trailing-edge hardware for these specific workloads. Long-context inference tasks are particularly important for reasoning, agentic AI, and automated research applications. The capacity of trailing-edge hardware to support these AI capability-enhancing tasks strengthens China’s ability to advance AI progress despite hardware constraints on cutting-edge GPUs..
Implications for Export Controls
The implications for export controls are significant: inference capacity is growing across the board, and restrictions on cutting-edge hardware won’t prevent China's inference capacity from expanding. Cutting-edge GPUs will retain significant performance advantages for short and medium-context workloads, but trailing-edge hardware remains surprisingly effective for long-context inference where memory constraints persist.
The prolonged viability of trailing-edge GPUs for inference extends the lifespan of China's existing hardware stockpile. Even as export controls limit China’s access to cutting-edge AI accelerators, China’s large stock of A100, A800, and H800 GPUs remains useful for inference applications far longer than they would for training. This sustains China's AI infrastructure and boosts its inference capacity despite limits on acquiring new chips.
Moreover, China has developed indigenous AI chips capable of inference. Huawei's Ascend 910C has demonstrated competitive performance for inference workloads. Notably, the Ascend 910C’s yield rate has doubled since last year to 40%, and Huawei plans to produce 100,000 units of the 910C and 300,000 units of the 910B in 2025, signaling a significant expansion of domestic chip production. Biren Technology's BR100, a 7nm, 77-billion transistor GPU, rivals the A100 for both training and inference. China’s growing production of inference-viable chips, substantial stockpile of trailing-edge GPUs, and continued access to the H20 reinforce its ability to sustain AI capabilities in an inference-heavy AI paradigm despite restrictions on acquiring cutting-edge hardware.
The Hardware Multiplier: China’s Inference Efficiency
Beyond hardware access, China’s advances in inference efficiency have significant strategic implications for U.S. export controls. DeepSeek’s recent innovations — particularly its v3 and R1 models — demonstrate China’s ability to push the frontier of inference efficiency. By implementing innovative techniques like a sparse Mixture of Experts architecture, multi-head latent attention, and mixed precision weights, DeepSeek’s R1 model achieves approximately 27x lower inference costs than OpenAI’s o1 while maintaining competitive performance.
This efficiency advantage effectively counterbalances U.S. hardware restrictions. Even if export controls limit China to 15x less hardware capacity, a 30x inference efficiency advantage would enable China to run nearly twice as much inference as the U.S. This acts as a multiplier on China’s hardware base, potentially giving China greater total inference capacity despite hardware restrictions.
The efficiency gains extend the utility of trailing-edge GPUs in China’s AI ecosystem, as improved inference efficiency compensates for computational and memory limitations. While DeepSeek’s achievements are a continuation of the observed decline in inference costs, this case demonstrates that Chinese AI labs have already developed the expertise to push the frontier of inference efficiency and could choose to withhold future breakthroughs if strategic considerations change.
The Sleeping Dragon: China’s Compute Overcapacity
Additionally, China’s massive but fragmented compute ecosystem is structurally better aligned with inference requirements than training needs. The aggressive GPU stockpiling during China’s “Hundred Model War” of 2023 created substantial compute capacity that became underutilized as many firms abandoned their foundation model ambitions. As Alibaba Cloud researcher An Lin observed, many of China’s claimed “10,000-GPU clusters” are actually collections of disconnected GPUs distributed across different locations or models. While this fragmentation makes the infrastructure suboptimal for training frontier models, it remains viable for inference workloads that can run effectively on smaller, distributed clusters.
Open-source models are particularly well-positioned to leverage this distributed infrastructure, enabling deployment across China’s fragmented GPU ecosystem and transforming previously idle compute into a strategic asset for widespread inference. This approach allows companies to preserve limited high-quality compute for model development while unlocking latent compute capacity.
China’s once-idle compute resources are increasingly valuable in an inference-heavy AI landscape, improving China’s position along both the innovation and diffusion axes.
How Should the U.S. Respond?
An inference-heavy AI paradigm favors China’s AI innovation potential. Its access to inference-viable hardware, leading inference efficiency, and compute overcapacity function better in an inference-driven context than in a pre-training one. U.S. export controls, designed to constrain training, have been less effective at limiting inference. China’s inference capacity remains underestimated. Despite restrictions, access to trailing-edge GPUs, stockpiles, domestic chips, and H20s enable continued progress.
As inference becomes central to AI competition, China’s relative position strengthens, narrowing the U.S. advantage. This shift demands a strategic recalibration: the U.S. must reinforce export controls and develop a coherent open-source AI strategy.
Restricting Exports of the NVIDIA H20
Export controls on AI hardware operate with a lag — typically one to two years before their full impact materializes. This lag effect is central to understanding both current policy outcomes and future strategic decisions for export controls.
Some cite DeepSeek’s latest models as proof that U.S. export controls have failed. However, this outcome is a shortcoming in how the controls were initially calibrated rather than a failure of the broader strategy. The Biden administration initially set narrow thresholds—based on FLOPs and interconnect bandwidth — which NVIDIA circumvented with the H800, designed specifically to remain exportable to China. When controls finally expanded to include the H800 in October 2023, Chinese companies had already stockpiled these GPUs in addition to speculated H100s and H20s, allowing them to maintain frontier development and delaying the policy's actual impact.
This lag highlights how AI hardware and model lifecycles can stretch over many months, so chips purchased immediately before or soon after a policy shift can remain in service for a long time. Consequently, the policy’s full impact may not be evident right away. As older hardware loses its edge for training and frontier development scales, the impact of controls becomes realized through constraints on both the speed of a country’s AI advancement and the extent of its diffusion.
The lag effect of export restrictions is more pronounced for inference hardware. Unlike training, inference workloads can remain viable on older GPU generations for much longer periods, as they depend more on memory capacity and bandwidth than raw compute power. If the U.S. delays restricting inference-oriented chips like the H20 until inference becomes even more central to AI power, the extended lag could substantially weaken the effectiveness of export controls as a defensive measure. By restricting the H20 now, the U.S. can meaningfully limit China’s accumulation of inference hardware before inference becomes the dominant compute paradigm in AI. The sooner these revised controls take effect, the sooner they will impose measurable constraints on China’s ability to compete along both axes of AI competition.
A Strategy for Open-Source AI
Open-source AI is a key vector of competition that requires a strategic U.S. approach. While it fuels innovation, not all models or circumstances warrant taking the same open approach. Open-sourcing an advanced model represents a form of technology transfer to China if that model exceeds the AI capabilities that China has access to. This reduces the U.S. lead on the AI innovation axis, shifting competition toward the diffusion axis — an area where China may be better positioned to compete.
As the compute requirements for pre-training grow, open releases help China overcome its pre-training disadvantage while amplifying the role of inference, where China is stronger. If not managed strategically, open-source AI could accelerate China’s ability to close the gap in both innovation and diffusion. The U.S. must assess whether it retains an edge in leveraging open models for research, application, and deployment. If so, open-source strategies can reinforce leadership; if not, they risk eroding it.
To assess the impact of an open release on U.S. tech competitiveness, we should evaluate how much of an immediate advantage the U.S. is foregoing on the AI innovation axis by open-sourcing a model and compare that to the net effect of how well the U.S. and China can convert open access into gains across both axes. If the U.S. retains a structural advantage in furthering AI research, building applications, fine-tuning, and scaling AI deployment, then open-source strategies can reinforce U.S. leadership. However, if China is more effective at leveraging open models for research, real-world adoption and economic or military applications, then unrestricted open release could benefit China more. This dynamic underscores the need for a structured approach and collaboration between private and public sector regarding deployment decisions.
The Bottom Line
As trends in AI elevate the importance of inference, the U.S. must reassess its strategy to lead along both axes of AI competition. While early export controls are designed to constrain China’s ability to train frontier models, they are less effective in limiting its capacity for large-scale inference. To sustain its competitive edge, the U.S. must expand export controls to address the growing role of inference, particularly by restricting chips like the NVIDIA H20 before their strategic importance escalates further. At the same time, the U.S. must refine its approach to open-source AI, ensuring that its diffusion benefits reinforce, rather than undermine, U.S. national AI leadership. Winning the AI competition requires adapting as fast as the technology evolves, and this is a critical moment for the U.S. to recalibrate its strategy.
For better or worse, it seems BIS' philosophy has always been to allow the flow of inference chips into China. They have never targeted memory bandwidth despite the obvious implications around inference performance. Even December’s HBM-focused update specifically exempts memory chips "affixed to a logic integrated circuit."
Steelmanning their approach a bit... inference will likely constitute 90%+ of future AI lifecycle compute demand. Letting this market go to Chinese domestic chip makers would allow these firm to channel that revenue towards R&D spend on training chips. Blocking this reinvestment widens the gap between Nvidia/AMD and Chinese indigenous hardware companies. Depriving Chinese labs access to SOTA “training HW” hinders frontier model development without stymieing diffusion.
This all falls apart as frontier model development shifts towards RL-heavy pipelines. Today, leading labs are likely reallocating compute away from pre-training towards RL-heavy post-training approaches. Here, inference chips become more useful (harvesting samples, reward modeling, etc.).
Are inference efficiency gains in China transferable to the West? Or are those improvements in inference not replicable by western firms?