


China’s New AI Regulations: Are They Enforcable?
“Let’s just treat it as a beautiful vision for humanity.”
The Cyberspace Administration of China, the country’s all-powerful internet watchdog, released a draft regulation targeting generative AI for public comment on April 11. Much attention has been paid to its Article 4 (1), a clause perhaps emblematic of the CAC’s approach:
Content generated using generative AI shall embody the Core Socialist Values and must not incite subversion of national sovereignty or the overturn of the socialist system, incite separatism, undermine national unity, advocate terrorism or extremism, propagate ethnic hatred and ethnic discrimination, or have information that is violent, obscene, or fake, as well as content that might disrupt the economic or social order.

It’s a tall order that does not deviate much from the wider internet censorship apparatus. China’s central authorities evidently believe that generative AI has the ability to threaten both national security and political stability, with a particular emphasis on domestic ethnocultural divisions. The CAC will, as expected, be able to interpret Core Socialist Values according to political priorities. And as Jordan and Nicholas argued in a previous piece on ChinaTalk, the vague yet palpable danger of crossing red lines will limit capacity for innovation among Chinese firms vying to compete with the likes of OpenAI.
China’s aspirations to become a world-leading AI superpower are fast approaching a head-on collision with none other than its own censorship regime. The Chinese Communist Party (CCP) prioritizes controlling the information space over innovation and creativity, human or otherwise. That may dramatically hinder the development and rollout of LLMs, leaving China to find itself a pace behind the West in the AI race.
How might CAC enforce its own rules? And how dramatically could they impact the course of AI development in China? Below is a look into how the regulations attempt to address:
Copyright and misinformation;
User participation in content moderation;
Training data transparency;
And deterring providers.
(I referenced China Law Translate’s full translation of the new regulations for this piece. The DigiChina Project has put together another translation.)
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.
Will Labels Solve Copyright and Misinformation?
Back in January, the CAC first required AI-generated content to be labelled. This made it into the new regulations:
Article 16: Providers shall label generated content such as images and video in accordance with the Regulations on the Administration of Deep Synthesis of Internet Information Services.
Wenxin Yige, Baidu’s image-generation model, already watermarks all generated images. There’s nothing stopping you from screenshotting though, and AI-generated text is not bound by similar rules.
The CAC repeatedly stresses the importance of factual accuracy — a very real challenge faced by large language models — in the new regulations. Article 4 (4) requires providers to implement measures to “prevent the generation of fake information.” Article 7 (4) asks providers to fact-check all training data, which is surely a herculean task. Baidu’s ERNIE is already no stranger to inaccuracies or hallucination; the technology, in its publicly available form, is simply not able to fully comply.
Getting Users Onboard
Article 18 specifies: “When users discover that generated content does not meet the requirements of these Measures, they have the right to make a report to the internet information departments or relevant competent departments.”
This is in line with regulations enforced upon existing Chinese internet platforms, where users already participate in a significant amount of political moderation and censorship. With generative AI, users may play an even larger role in enforcement. Individual netizens may not always want to file reports in case the CAC pulls the plug on their favourite chatbot, but others, not least competitors and the media, will happily expose compliance failures in various models.
If a report is made, Article 15 provides a grace period: providers have three months’ time to employ “means such as model optimization training” and prevent their models from violating regulations again after a first offense. Chinese authorities are aware that generative AI is not an easily tamed beast, and this clause may give it a way out of shutting down too many AI products.
Disclosing the Training Datasets
Article 17 requires that generative AI providers “... provide necessary information that can impact user confidence or selections, including descriptions of the sources, scale, types, and quality of pre-training and optimization training data, the rules for manual tagging, the scale and types of manual tagging data, foundational algorithms and technical systems, and so forth.”
It’ll be fascinating to watch how Chinese big tech responds to this particular clause. It seems to hold Chinese generative AI up to a very high standard of transparency, at a time when US-based AI firms are having second thoughts about revealing the contours of their models’ training datasets.
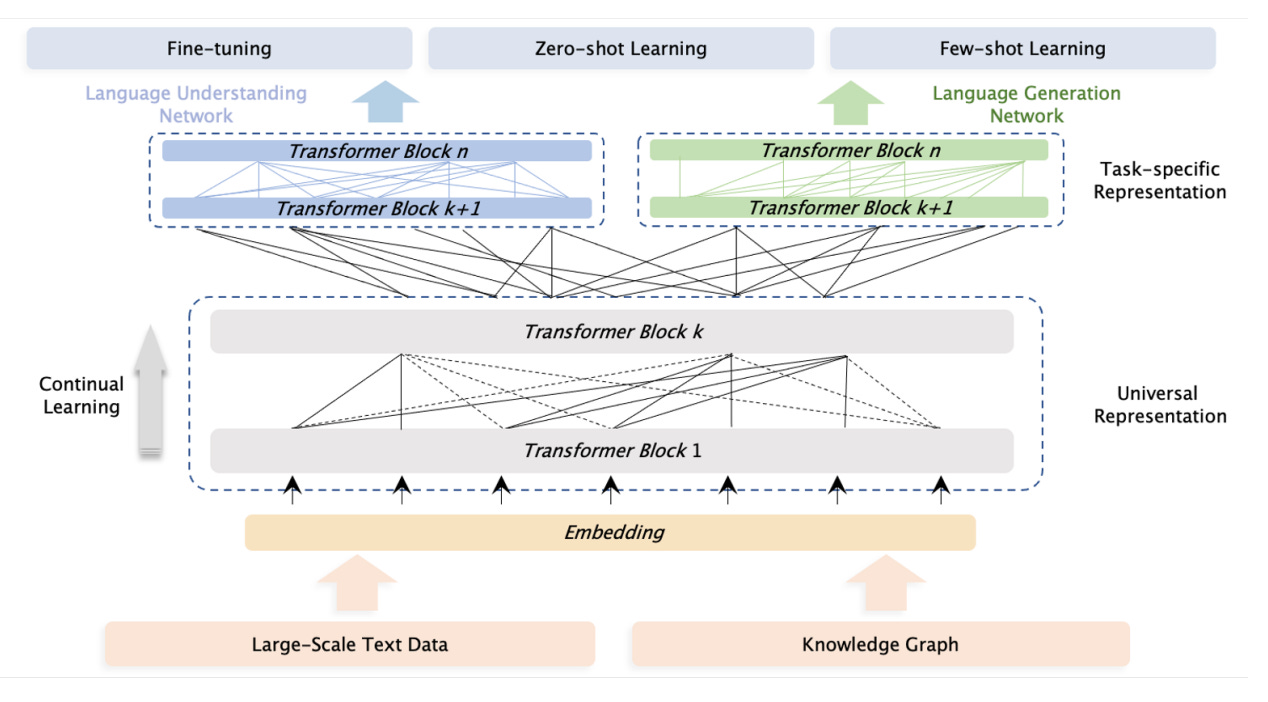
Baidu, in a 2021 paper, described its pre-training data for ERNIE as such: “In detail, we build the corpus for ERNIE 3.0 based on that from ERNIE 2.0 (including baike, wikipedia, feed and etc), Baidu Search (including Baijiahao, Zhidao, Tieba, Experience), Web text, QA-long, QA-short, Poetry & Couplet, [and] domain-specific data from medical, law and financial area and Baidu knowledge graph with more than 50 million facts.” At the ERNIE Bot launch in March 2023, CEO Robin Li further explained that the model is trained on “trillions of web page data, tens of billions of search and image data, hundreds of billions of daily voice data, as well as a knowledge graph consisting of 55 trillion facts and more.” These vague disclosures are unlikely to be satisfactory. While they give a peek into the scale and quality of ERNIE’s training, it does not address the other concerns CAC named in its draft regulation: political security, bias, and factual accuracy.
If these measures do come into force in their current form, Chinese regulators will likely push AI developers to disclose a lot more than they currently do. Article 7 says that in addition to legality and copyright compliance, generative AI providers must also “ensure the truth, accuracy, objectivity, and diversity of the data.” As Kevin Xu of the Interconnected Substack notes here, “diversity” may be a purposefully vague term that further empowers the CAC to inspect training data.
What Are The Punishments?
Articles 19 and 20 go into what may happen if a generative AI provider fails to comply.
Article 19: When providers discover users have violated laws or regulations, or have conduct that is contrary to commercial ethics or social mores during their use of generative AI products, including engaging in online hype, malicious posting of comments, spam generation, compiling malicious software, or carrying out improper commercial marketing, they shall suspend or stop services.
As many Chinese commentators have noted, the measures as a whole place the burden of compliance squarely on the shoulders of providers, rather than users. Article 19 seems to indicate that the harshest punishment a user might face for using generative AI improperly is loss of access to services. However, Article 9 requires providers to collect users’ real identity information (similar to Chinese social media platforms), so any action is still traceable to the individual if a provider is compelled to investigate.
Article 20 indicates that the CAC will try to use existing legal instruments like the Data Security Law, the Cybersecurity, and the Law on the Protection of Personal Information to address generative AI-related violations as much as possible. Where that is impossible, it will issue a warning to first-time offenders. But “where corrections are refused or the circumstances are serious”, providers face suspension, termination of services, and a fine of between 10,000 and 100,000 RMB ($1,463 to $ 14,628). The financial penalties aren’t harsh, but criminal investigations are a real possibility.
Reactions from the Chinese Legal Community
China’s censors have been extremely effective at pacifying public opinion, atomizing grassroots movements, and enforcing amnesia regarding historical events. But on a granular level, it is a reactive, manual, and sometimes haphazard machine. The “white paper” protests last November saw the system struggling to cope with the sheer amount of footage being shared online, as users distributed content back and forth across the Great Firewall. This setup is not yet ready to regulate the internet in the era of generative AI, which endlessly churns out multimodal content and might even get better than humans at evading censorship.
China’s legal community has struck a hesitant tone in response to the regulations. Many seem unconvinced that they can be enforced effectively in their current form.
Below, we recap four leading Chinese lawyers’ takes on the new regulations with translations of their reactions.