
DeepSeek and the Future of AI Competition with Miles Brundage
terrible takes can't stand uncorrected
I recorded a show yesterday afternoon with Miles Brundage, who recently left OpenAI after six years running its Policy Research and AGI Preparedness teams. See our transcript below I’m rushing out as these terrible takes can’t stand uncorrected.
Or have a listen on Apple Podcasts, Spotify or your favorite podcast app.
Initial Model Impressions
Jordan: Let’s start with the news. What is remarkable about their latest R1 model?
Miles: I think compared to GPT3 and 4, which were also very high-profile language models, where there was kind of a pretty significant lead between Western companies and Chinese companies, it’s notable that R1 followed pretty quickly on the heels of o1. It’s a model that is better at reasoning and kind of thinking through problems step-by-step in a way that is similar to OpenAI’s o1.
So o1 inspired R1, but it didn’t take very long, about two months. And that has rightly caused people to ask questions about what this means for tightening of the gap between the U.S. and China on AI.
Jordan: What are your initial takes on the model itself?
Miles: I think it’s good. Honestly, there’s a lot of convergence right now on a pretty similar class of models, which are what I maybe describe as early reasoning models. It’s similar to, say, the GPT-2 days, when there were kind of initial signs of systems that could do some translation, some question and answering, some summarization, but they weren't super reliable.
We’re at a similar stage with reasoning models, where the paradigm hasn’t really been fully scaled up. But certainly, these models are much more capable than the models I mentioned, like GPT-2. But it’s notable that this is not necessarily the best possible reasoning models. It's just the first ones that kind of work.
And there are several models like R1, Alibaba’s QwQ. R1 is probably the best of the Chinese models that I’m aware of. And then there’s a bunch of similar ones in the West. So there’s o1. There’s also Claude 3.5 Sonnet, which seems to have some kind of training to do chain of thought-ish stuff but doesn’t seem to be as verbose in terms of its thinking process. And then there is a new Gemini experimental thinking model from Google, which is kind of doing something pretty similar in terms of chain of thought to the other reasoning models.
They’re all broadly similar in that they are starting to enable more complex tasks to be performed, that kind of require potentially breaking problems down into chunks and thinking things through carefully and kind of noticing mistakes and backtracking and so forth.
Jordan: When you read the R1 paper, what stuck out to you about it?
Miles: I mean, honestly, it wasn’t super surprising. There were some interesting things, like the distinction between R1 and R1.0 — which is a riff on AlphaZero — where it’s starting from scratch rather than starting by imitating humans first. But broadly speaking, I wasn’t surprised because I worked at OpenAI and was familiar with o1. I spent months arguing with people who thought there was something super fancy going on with o1. They were saying, “Oh, it must be Monte Carlo tree search, or some other favorite academic technique,” but people didn’t want to believe it was basically reinforcement learning—the model figuring out on its own how to think and chain its thoughts.
For some people that was surprising, and the natural inference was, “Okay, this must have been how OpenAI did it.” There’s no conclusive evidence of that, but the fact that DeepSeek was able to do this in a straightforward way — more or less pure RL — reinforces the idea. Just today I saw someone from Berkeley announce a replication showing it didn’t really matter which algorithm you used; it helped to start with a stronger base model, but there are multiple ways of getting this RL approach to work.
DeepSeek basically proved more definitively what OpenAI did, since they didn’t release a paper at the time, showing that this was possible in a straightforward way. It has interesting implications. It also speaks to the fact that we’re in a state similar to GPT-2, where you have a big new idea that’s relatively simple and just needs to be scaled up.
Squaring Distilled Models and The Stargate Announcement
Jordan Schneider: The piece that really has gotten the internet a tizzy is the contrast between the ability of you to distill R1 into some really small form factors, such that you can run them on a handful of Mac minis versus the split screen of Stargate and every hyperscaler talking about tens of billions of dollars in CapEx over the coming years.
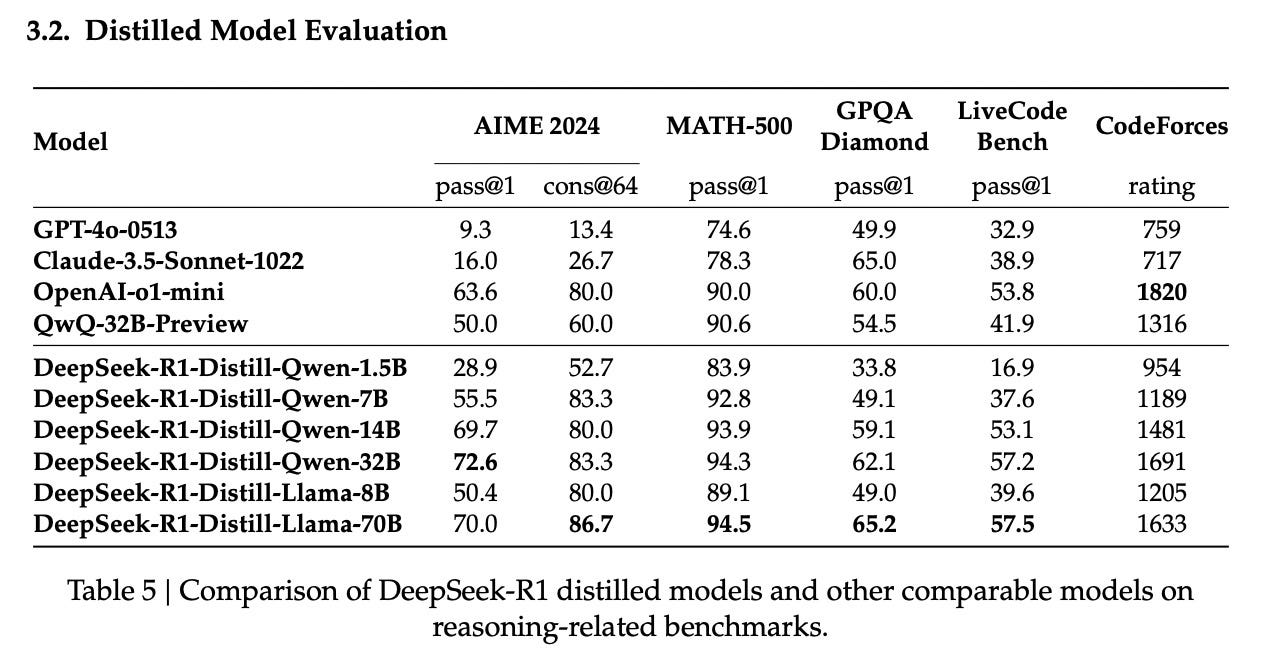
Square the circle for me here, Miles. What does and doesn’t R1 tell you about to what extent compute is going to be necessary to reap the gains of AI in the coming years?
Miles Brundage: It’s a great question. And, you know, for those who don’t follow all of my tweets, I was just complaining about an op-ed earlier that was kind of saying DeepSeek demonstrated that export controls don’t matter, because they did this on a relatively small compute budget.
I think that’s the wrong conclusion. I think it certainly is the case that, you know, DeepSeek has been forced to be efficient because they don’t have access to the tools — many high-end chips — the way American companies do. And they’ve said this quite explicitly, that their primary bottleneck is U.S. export controls. As the CEO said in an interview you translated, “Money has never been the problem for us; bans on shipments of advanced chips are the problem.”

That doesn’t mean they wouldn’t prefer to have more. Turn the logic around and think, if it’s better to have fewer chips, then why don’t we just take away all the American companies’ chips? Clearly there’s a logical problem there.
Certainly there’s a lot you can do to squeeze more intelligence juice out of chips, and DeepSeek was forced through necessity to find some of those techniques maybe faster than American companies might have. But that doesn’t mean they wouldn’t benefit from having much more. That doesn’t mean they are able to immediately jump from o1 to o3 or o5 the way OpenAI was able to do, because they have a much larger fleet of chips.
People are reading too much into the fact that this is an early step of a new paradigm, rather than the end of the paradigm. These are the first reasoning models that work. This is the first demonstration of reinforcement learning in order to induce reasoning that works, but that doesn’t mean it’s the end of the road. I think everyone would much prefer to have more compute for training, running more experiments, sampling from a model more times, and doing kind of fancy ways of building agents that, you know, correct each other and debate things and vote on the right answer. So there are all sorts of ways of turning compute into better performance, and American companies are currently in a better position to do that because of their greater volume and quantity of chips.
Implications of DeepSeek’s Model Distillation
Jordan Schneider: Can you talk about the distillation in the paper and what it tells us about the future of inference versus compute? The premise that compute doesn’t matter suggests we can thank OpenAI and Meta for training these supercomputer models, and once anyone has the outputs, we can piggyback off them, create something that’s 95 percent as good but small enough to fit on an iPhone.
Miles: It’s unclear how successful that will be in the long term. Even if you can distill these models given access to the chain of thought, that doesn’t necessarily mean everything will be immediately stolen and distilled.
There are rumors circulating that the delay in Anthropic’s Claude 3.5 Opus model stems from their desire to distill it into smaller models first, converting that intelligence into a cheaper form. They apparently want to control the distillation process from the large model rather than letting others do it.
Companies will adapt even if this proves true, and having more compute will still put you in a stronger position. The implications for APIs are interesting though. If someone exposes a model capable of good reasoning, revealing these chains of thought might allow others to distill it down and use that capability more cheaply elsewhere.
Some companies have started embracing this trend. OpenAI provides a fine-tuning service, acknowledging the benefits of smaller models while keeping users on their platform rather than having them use their own model.
The space will continue evolving, but this doesn’t change the fundamental advantage of having more GPUs rather than fewer. Consider an unlikely extreme scenario: we’ve reached the absolute best possible reasoning model — R10/o10, a superintelligent model with hundreds of trillions of parameters. Even if that’s the smallest possible version while maintaining its intelligence — the already-distilled version — you’ll still want to use it in multiple real-world applications simultaneously.
You wouldn’t want to choose between using it for improving cyber capabilities, helping with homework, or solving cancer. You’d want to do all of these things. This requires running many copies in parallel, generating hundreds or thousands of attempts at solving difficult problems before selecting the best solution. Even in this extreme case of total distillation and parity, export controls remain critically important.
To make a human-AI analogy, consider Einstein or John von Neumann as the smartest possible person you could fit in a human brain. You would still want more of them. You’d want more copies. That’s basically what inference compute or test-time compute is — copying the smart thing. It’s better to have an hour of Einstein’s time than a minute, and I don’t see why that wouldn’t be true for AI.
No, You Don’t Just Give Up on Export Controls
Jordan Schneider: For the premise that export controls are useless in constraining China’s AI future to be true, no one would want to buy the chips anyway.
Miles: Exactly. People sometimes conflate policies having imperfect results or some negative side effects with being counterproductive. While export controls may have some negative side effects, the overall impact has been slowing China’s ability to scale up AI generally, as well as specific capabilities that originally motivated the policy around military use.
Jordan Schneider: What’s your fear about the wrong conclusion from R1 and its downstream effects from an American policy perspective?
Miles: My main concern is that DeepSeek becomes the ultimate narrative talking point against export controls. While I don’t think the argument holds, I understand why people might look at it and conclude that export controls are counterproductive. They are being efficient — you can’t deny that’s happening and was made more likely because of export controls.
However, the more extreme conclusion that we should reverse these policies or that export controls don’t make sense overall isn’t justified by that evidence, for the reasons we discussed. My concern is that companies like NVIDIA will use these narratives to justify relaxing some of these policies, potentially significantly. This might have some marginal positive impact on companies’ revenue in the short term, but it wouldn't align with the administration’s overall policy agenda regarding China and American leadership in AI.
If you’re DeepSeek and currently facing a compute crunch, developing new efficiency methods, you’re certainly going to want the option of having 100,000 or 200,000 H100s or GB200s or whatever NVIDIA chips you can get, plus the Huawei chips. Having access to both is strictly better. This is a straightforward case that people need to hear — it’s clearly in their benefit for these export controls to be relaxed. We shouldn’t be misled by the specific case of DeepSeek.
Those familiar with the DeepSeek case know they wouldn’t prefer to have 50 percent or 10 percent of their current chip allocation. Nobody wants fewer chips. Yes, you have to be more efficient when you have less, but everyone would prefer to have more, and relaxing our policies would only help them.
Jordan Schneider: A longer-term question might be: if model distillation proves real and fast following continues, would it be better to have a more explicit set of justifications for export controls?
Honestly, I always thought the Biden administration was somewhat disingenuous talking about “small yard, high fence” and defining it solely as military capabilities. That’s where the compute will go first, but if you’re talking about long-term strategic competition, much of how the Cold War was ultimately resolved came down to differential growth rates. When considering national power and AI’s impact, yes, there’s military applications like drone operations, but there’s also national productive capacity. From that perspective, you want a hundred von Neumanns rather than five to help with broader economic growth, not just hardening missile silos.
Miles: I agree about the somewhat disingenuous framing. The U.S. clearly benefits from having a stronger AI sector compared to China’s in various ways, including direct military applications but also economic growth, speed of innovation, and overall dynamism.
There are multiple reasons why the U.S. has an interest in slowing down Chinese AI development. However, to be clear, this doesn’t mean we shouldn’t have a policy vision that allows China to grow their economy and have beneficial uses of AI. We don’t necessarily need to choose between letting NVIDIA sell whatever they want and completely cutting off China. There should probably be something more nuanced with more fine-grained controls.
But that requires work to sort out and requires properly staffing the Department of Commerce to implement detailed agreements around keeping certain technologies for civilian purposes while preventing others from going to military uses [See Greg Allen, Emily Benson (now working at BIS), and Bill Reinsch on some very sensible and affordable reforms to upgrade BIS’ capabilities]. Without that capacity and without innovation in technical tooling, potentially including trackers on chips and similar measures, we’re forced into this all-or-nothing paradigm.
It’s unfortunate because this situation has numerous negative consequences. There are legitimate beneficial uses for AI in China, but we’re currently stuck between these extreme choices because we haven’t invested in those long-term fundamentals. Commerce can barely turn around rules in response to NVIDIA’s latest chips, let alone implement anything more sophisticated.
Open-Sourced Frontier Models
Jordan: What does it mean that this model got open-sourced?
Miles: It’s super interesting. DeepSeek is similar to Meta in being explicitly pro-open source — even more so than Meta. They’ve made an explicit long-term commitment to open source, while Meta has included some caveats.
I’m not sure how much we should believe that commitment. As AI systems become more capable, both DeepSeek employees and the Chinese government will likely start questioning this approach. I don’t actually believe it will continue, and I’m not convinced it’s in the world's long-term interest for everything to always be open-sourced.
Many things should be open-sourced, though. When things are open-sourced, legitimate questions arise about who’s making these models and what values are encoded in them. There are also potential concerns that haven’t been sufficiently investigated — like whether there might be backdoors in these models placed by governments. From a U.S. perspective, there are legitimate concerns about China dominating the open-source landscape, and I’m sure companies like Meta are actively discussing how this should affect their planning around open-sourcing other models.
The U.S. government needs to strike a delicate balance. It would be a mistake to lock in a policy of unconditional support for open source forever. The decision to release a highly capable 10-billion parameter model that could be valuable to military interests in China, North Korea, Russia, and elsewhere shouldn’t be left solely to someone like Mark Zuckerberg. The government needs to be involved in that decision-making process in a nuanced way. However, completely cutting off open source would also be a mistake. Both companies and the U.S. government should be considering how to respond to DeepSeek’s current leadership in this space.
Jordan Schneider: This is my base case too. The Trump administration just recently said they were going to revoke the AI executive order — the only thing remaining really was the notification requirement if you’re training a giant model.
This doesn’t seem sustainable as a steady state, either in China or in the West. These models are fine, cute, and fun now — they’re not really super dangerous. But we’re not far from a world where, until systems are hardened, someone could download something or spin up a cloud server somewhere and do real damage to someone’s life or critical infrastructure. That’s not a world government officials in Beijing or the West want to live in.
The eye of Sauron has now descended upon DeepSeek. Li Qiang, the Chinese premier, invited DeepSeek’s CEO to an annual meet-and-greet with the ten most notable Chinese people they select each year. The AI representative last year was Robin Li, so he’s now outranking CEOs of major listed technology companies in terms of who the central leadership decided to give shine to. That’s impressive, but it also means the Chinese government is really going to start paying attention to open-source AI.
In the past, there have been some industries where it was particularly helpful for Chinese industry to coalesce around open-source. With RISC-V, there’s no social stability risk of people using that instruction set architecture instead of ARM to design chips. Letting models run wild in everyone’s computers would be a really cool cyberpunk future, but this lack of ability to control what’s happening in society isn’t something Xi’s China is particularly excited about, especially as we enter a world where these models can really start to shape the world around us. Color me skeptical.

Miles: We haven’t done serious hardening yet. We don’t have CAPTCHA systems and digital identity systems that are AI-proof over the long term without leading to Orwellian outcomes. There are open vulnerabilities to AI systems running wild in the West. We’re also not well-prepared for future pandemics that could be caused by deliberate misuse of AI models to produce bioweapons, and there continue to be all sorts of cyber vulnerabilities.
We could eventually reach a point where we’ve built those defenses and feel more confident letting it rip, at least in the U.S. I don’t know whether China is ready for this kind of wild west situation of AIs running everywhere, being customized on devices, and fine-tuned to do things that might differ from the Party line. There might be a scenario where this open-source future benefits the West differentially, but no one really knows. The technology is still developing — it’s not in a steady state at all. I’m an open-source moderate because either extreme position doesn't make much sense.
Jordan: The Chinese regulatory architecture around bringing models to market has entirely focused on content moderation. You basically need to submit it and score well on questions about Tiananmen, Xinjiang, Xi, and the constitution. But you can do that and still be able to turn off the lights in a city. Once we live in that future, no government — any government — wants random people having that ability.
China’s GenAI Content Security Standard: An Explainer

Last year, Nancy Yu revealed how Chinese computer engineers program censorship into their chatbots, and Bit Wise wrote a groundbreaking report on the regulatory framework behind that censorship mandate — “SB 1047 with Socialist Characteristics.”
That world is probably a lot more likely and closer thanks to the innovations and investments we’ve seen over the past few months than it would have been a few years back. So, buckle up.
Miles: These reasoning models are reaching a point where they’re starting to be super useful for coding and other research-related purposes, so things are going to speed up. Despite some folks’ views, not only will progress continue, but these more dangerous, scary scenarios are much closer precisely because of these models creating a positive feedback loop.
I don’t think it’s going to happen overnight. For now, humans are in the driver’s seat of the research process, but these are extremely useful tools that DeepSeek, Meta, and others are using internally to improve their productivity. Even though a year feels like a long time — that’s many years in AI development terms — things are going to look quite different in terms of the capability landscape in both countries by then.
Export Controls Will Still Be a Key Piece of the Competition
Jordan: Closing thoughts, Miles?
Miles: No one believes the current export control system is perfect. Some people would prefer it to be stronger in some ways or weaker in others, but the main thing we should remember is that imperfect is not the same as counterproductive.
When people say “DeepSeek clearly shows X, Y, and Z,” they’re often pointing to examples of imperfections, like how we haven’t completely stopped Chinese AI progress, or how it led to more efficiency in specific contexts. That’s very different from saying it’s counterproductive.
Even if it had been counterproductive in the past, that doesn’t necessarily mean we’re stuck with the current policy. Perhaps they’ve invested more heavily in chips and their own chip production than they would have otherwise — I’m not sure about that. But they’re still behind, and export controls are still slowing them down.
Whether it’s the perfect policy or whether everything was done exactly right in the past is a separate question from whether we should maintain broadly similar direction with some course corrections versus reversing it entirely. My worry is that this will be taken as a sign that the whole direction is wrong, and I don't think there's any evidence of that.
Jordan: Got a song to take us out on?
Miles: How about something from Max Richter? Maybe something from The Leftovers, which I’d also like to plug as a good show. There’s this song called “The Departure” from the season one soundtrack of The Leftovers by Max Richter, which is very pleasant to listen to.
Jordan : Great. Perfect way to take us into our weekend. Miles, thanks so much for being a part of ChinaTalk.
Miles: Yeah, thanks so much for having me.
I think the nature of every release getting hyped to the moon is what’s driving the takes.
r1 has comparable performance as a prior model OpenAI came out with is less of a sexy headline than, “China is winning! The US messed up!” Just as the idea that Google was triumphant and OpenAI was washed with Veo/Sora lasted all of a couple of days before o3.
Perhaps it’ll be a good thing in spurring more competition and innovation, like Sputnik (… not that boiled down this is anywhere near the same level gap). But I think it’s more likely everyone will lose interest with the next release of whatever…
Great article.
Respectfully, I have a different perspective on expert controls, though. Export controls may work on small countries like Cuba, which don't have the capacity to develop their own. The notion, however, that export control would hold back China—other than in the short term—seems implausible. China is the second-largest economy in the world, and when measured in PPP GDP, it is the largest economy in the world. All we will do is incentivize the Chinese to develop their equivalent of Nvidia, catch up, and exceed us.
I fear that our 'self-confidence' in our exceptionalism is less and less based on reality (merit) and more and more based on ego.
As I want the US, my home country, to do well, that is not a good development.