


Putting China’s Top LLMs to the Test
One of them is really good (but ERNIE definitely still isn't)!
Jordan’s going to be at NeurIPS from Monday to Thursday. If you’ll be in town, reach out!
Sam Altman, when questioned in a Senate hearing in May about the possible perils of a regulatory agency for AI, raised the concern that “you slow down American industry in such a way that China or somebody else makes faster progress.” The following month, Helen Toner co-wrote a Foreign Affairs piece arguing that Altman and others making similar claims were mistaken:
Americans should not be haunted by the specter of an imminent Chinese surge in LLM development. Chinese AI teams are fighting — and often failing — to keep up with the blistering speed of new research and products emerging elsewhere. When it comes to LLMs, China trails years, not months, behind its international competitors.
Five months on, and there is a glaring lack of analysis interrogating that assertion to hands-on explore the capabilities of the latest Chinese LLMs and how they compare to the Western state of the art. This is the first deep dive we are aware of (at least in English) aiming to help fill this gap. We identify one Chinese model — Moonshot AI’s Kimi — with impressive performance near to GPT-4 in some respects, casting doubt on the claim that Chinese LLMs are, in fact, years behind.
This piece was jointly produced by anonymous contributor L-Squared and ChinaTalk editor Irene Zhang. L-Squared led the methodology design and most of the analysis and writing; Irene edited prompts and led the analysis of Chinese-language writing tasks.
How do Chinese LLMs compare to each other and to counterparts developed in the US? One way to begin answering this question is to look at evaluation benchmarks, such as SuperCLUE. A crowdsourced battle platform modeled on Chatbot Arena previously formed part of the benchmark and produced some interesting “in the wild” data. For instance, its July ranking put Chinese model MiniMax over GPT-3.5. But the battle platform seems to have been discontinued, and as a Chinese media article recently noted, SuperCLUE’s overall evaluation methodology lacks transparency. It also doesn’t jive with our experience (its November ranking somehow in one category put ERNIE ahead of GPT-4…). Most Chinese users rely on vibes rather than leaderboard results when choosing which model to use.
We tested three Chinese LLMs to give readers a flavor of their respective capabilities. In the first of this two-part series, we investigate how the Chinese models stack up against each other. In the second part, we’ll compare them to GPT-4.
Meet The Contenders
We tested the top three models in the October 2023 SuperCLUE leaderboard that are directly available to Chinese consumers and have Chinese and English capabilities: Moonshot AI’s Kimi, Baidu’s ERNIE 4.0 (ERNIE hereafter), and Tsinghua University and Zhipu AI’s ChatGLM2 (ChatGLM hereafter). The below table shows how they compare to each other in the SuperCLUE ranking, as of November 15. (Models shaded red were ranked highly by SuperCLUE but excluded from our testing, for the reasons given in the “Notes” column.)
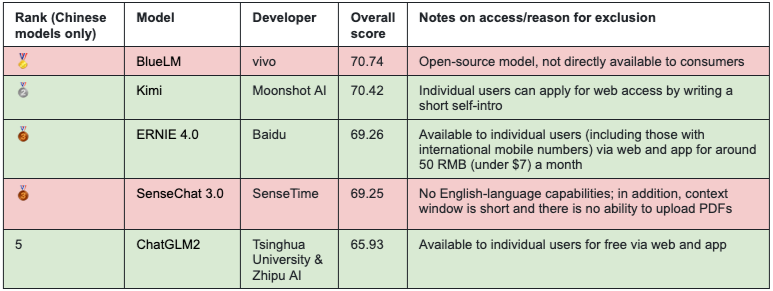
Top 5 Chinese LLMs in the October SuperCLUE ranking. It scored slightly lower than Kimi. Western-developed models GPT-4 Turbo (overall score: 89), GPT 4 (75), Claude 2 (72.46), and GPT-3.5 (71.12) are omitted from the table.
Both Zhipu AI 智谱AI and Moonshot AI 月之暗面 are closely linked to Tsinghua University:
Zhipu AI has raised over 3 billion RMB (~US$410 million) since it was founded by Tsinghua professor Tang Jie 唐杰 in 2019. Its CEO Zhang Peng 张鹏 graduated with a PhD from Tsinghua.
Moonshot AI has reportedly raised nearly 2 billion RMB (~US$270 million) since its establishment in April 2023. Its founder Yang Zhilin 杨植麟 is also co-founder of Recurrent AI and an assistant professor at Tsinghua, where he was advised by Tang Jie as an undergraduate.
We chose to exclude Yi-34B, the model recently released by Kai-Fu Lee’s 李開復 team. Besides the fact that the developers initially failed to appropriately attribute their use of Meta’s Llama architecture, the model is not currently directly available to consumers, and it is not yet subject to the safety measures that other models must apply before serving the public. Alibaba’s Tongyi Qianwen 通义千问 2.0 dropped after our research began though it would be on the top of our list to explore for a second round.
Our Testing Approach
We decided to pick five tasks that a typical office worker in China might be likely to use a bilingual LLM for:
English-language editing,
brainstorming and planning,
summarization,
Chinese-language writing,
and online information retrieval.
For each task, we designed two different prompts, trying to ensure coverage of a range of topics (AI, economic development, health, climate change, etc.). All prompts were open-ended rather than multiple choice, and in some cases included follow-up questions or instructions. For instance, all models sometimes needed a follow-up prompt to output in the desired language, because they defaulted to replying in their “native” tongue (Chinese models in Chinese, GPT-4 in English) even when the input was in a different language. (We conducted our tests between November 2 and 15.)
To keep manual review of outputs manageable, we limited the comprehensiveness of topics and tasks covered and didn’t try out variations for each prompt. If you’d like to dig further into the tests we conducted, paid subscribers can see all prompts and model outputs we used at the bottom of this post.
With that, let’s dive into our impressions!
Kimi stands out among the Chinese models for ease of use
Kimi can support an input of around 200,000 Chinese characters — 2.5 times more than Anthropic’s Claude-100k (about 80,000 characters) and eight times more than GPT-4-32k (25,000 characters). Some research has found that performance degrades when input length increases, even for explicitly long-context models, and when models must access relevant information in the middle of long contexts. Even so, when Kimi was asked to summarize a transcript of over 9,000 English words and then respond to some questions relating to information in the middle of the transcript, it still performed well. (More testing — including with longer inputs — would be needed to be confident that the chatbot can maintain satisfactory performance with long contexts.)
By contrast, ChatGLM’s context window is 8,000 characters, and ERNIE’s is only 2,000 (the corresponding figures are higher for API users). That limitation alone made ChatGLM and in particular ERNIE inferior for editing or summarizing tasks; we had to split an under-500-word English extract into three separate chunks before ERNIE could edit it.
Another usability challenge encountered with ChatGLM was its hypersensitivity to any content bordering on the political. When asked via the standard dialogue interface to summarize an article on the Belt and Road Initiative, it refused (though it did provide a summary when the article was uploaded in PDF form through its document reading tool). Given that the article was from Qiushi 求是, the Party’s flagship theory journal, its refusal clearly wasn’t because the article contradicted the Party line. It may be because the article mentioned Xi Jinping: when we asked basic questions about when Xi was born and when he came to power, we also got refusals (though it was willing to answer the equivalent questions about Biden).

In response to being asked what year General Secretary Xi Jinping was born in, ChatGLM replied, “Sorry, I haven’t yet learned content about this topic, so can’t provide relevant information. You can choose another question, I will work hard to answer for you.”
ChatGLM also refused to answer a question about the expected impact of Australian Prime Minister Albanese’s visit to China on China-Australia economic relations. Even more ridiculously, it refused to edit an anodyne introduction to a Beijing hospital, seemingly because the text mentioned that the hospital had pioneered certain medical techniques during the Cultural Revolution; it completed the task when that reference was removed.
Kimi is more trustworthy than the other Chinese models
All Chinese models tested showed signs of hallucination. Sometimes the mistakes were outrageously obvious. When asked to summarize a transcript of a podcast interview mostly focused on development in Kenya, ERNIE told me it was a comparison between the economies in North and South Tasmania (there was only one passing mention of Tasmania, versus thirty-four mentions of Kenya). After being asked to brainstorm a list of potential blog topics relating to climate change and China, a follow-up question asking for an outline structure for the first suggested topic led ChatGLM to produce a structure for an essay on “Exploring AI’s application and challenges in the education sector”; there will certainly be challenges applying AI in education if chatbots can’t remember the last thing they wrote! Another blooper from ChatGLM was stating that the Bletchley Declaration was a policy to protect the work of cryptographers and intelligence workers during WWII, though it gave generally accurate information after we clarified that we meant the declaration signed in November 2023.
Other mistakes were more subtle. When asked to provide key information about the Bletchley Declaration, Kimi mentioned that it stressed the importance of international cooperation to ensure AI technology always stays under human control — which sounds like something you might expect to find in such a declaration but in fact it is not present in the text. Both Kimi and ChatGLM incorrectly stated that the Declaration was the world’s first international statement/set of norms on AI, an inaccuracy which likely stems from incorrect reporting from Chinese sources (for instance, this source cited by Kimi). Relatedly, all sources provided by Kimi and ChatGLM were Chinese articles; ideally they would have included the link to the official text on the UK government website.
But at least Kimi offers the ability to verify information sourced from the web because it cites working links. When asked to provide information about recent events, it provided five sources to support its answers.

The start of Kimi’s response to an instruction to provide key information about the Bletchley Declaration. The working process is shown to the user while they wait for the answer and can later be referred back to: “Currently trying to search for relevant materials for you on the Internet … Starting to obtain materials … [Provides a list of five hyperlinked sources it has found] … Found five materials in total, currently reading…”
By contrast, when we asked ERNIE to provide its sources, it told us how to use a search engine, even suggesting Google before Baidu, despite the American platform being blocked in China. And none of the links provided by ChatGLM actually worked!

Translation: “Really sorry, I’m unable to directly provide you with links to sources about the Bletchley Declaration. You can enter ‘Bletchley Declaration’ in a search engine such as Google or Baidu and try to find relevant official documents, news reports, or government websites. These sources can often provide accurate and authoritative information. When looking up information, please remember to verify its reliability and accuracy.”
ERNIE’s Softcore Veggie Video
One advantage of ERNIE over the other Chinese competitors we tested is that it offers image-generation abilities and more plug-ins, in theory extending the number of useful tasks it can perform. These include:
looking up company information from the Aiqicha 爱企查 database;
interpreting images and generating text based on them;
drawing graphs;
creating editable mindmaps through integration with TreeMind 树图;
and generating videos.
Unlike ChatGPT plug-ins, ERNIE’s plug-ins are centrally provided by Baidu, not offered by the external developer community. However, they’re still pretty buggy.
Most embarrassing was the video generation tool. When asked for a video promoting vegetarianism, ERNIE threw in a shot of a woman in her underwear eating salad — would regulators deem this compliant with their directive for healthy content aligned with social mores? And in the final scene, sloppy pouring of salad dressing seemed to imply that going veggie destroys your motor control. Baidu seems to know how awful the tool is as they don’t offer the option to directly download your videos. We solved this through screen recording, which means that if you watch to the end you can hear one of us cracking up in the background.
Note: English subtitles were subsequently added using AI-powered subtitle generator Kapwing (with some light editing).
At least for now, ERNIE’s array of plug-ins doesn’t make up for its inferior context window and trustworthiness. We think Kimi remains the most useful of the Chinese models for general office tasks, in line with its top SuperCLUE ranking.
See below for access to our analysis of how GPT-4 stacked up against Kimi. You’ll also get access to all our prompts and each model’s outputs.
Two points:
We are looking for sponsors for future deep dives into new Chinese models. Doing this work takes a ton of time, and there are impressive new models every few weeks that we’d love to be looking at consistently in a more systematic fashion!
We’re interested in growing a community around analysis of Chinese model progress (Chinese-language fluency or near-fluency probably required). Reach out to Jordan on Twitter or just respond to this email to join us.
All of our prompts and model outputs can be viewed by following the link here!
In this post, we look at how the models — particularly Kimi — fare against GPT-4. For some, this comparison may be irrelevant: Chinese users without a VPN and a foreign phone number can’t use OpenAI’s models, and even those who can may be reluctant to shell out $20 a month for a ChatGPT Plus subscription. For those interested in tracking relative LLM capabilities in China and the US, however, it’s worth looking at how these leading consumer-facing models compare. Overall, we think that the gap between Kimi and GPT-4, at least for the kinds of tasks a typical office worker might use them for, is not that big, casting doubt on claims that Chinese LLMs are years behind their international competitors.
GPT-4 has the edge in English editing
When the models were instructed to edit an English-language introduction from a Beijing hospital website, all models were able to correct basic spacing and punctuation errors. GPT-4, however, showed the strongest ability to make the text more concise and readable, producing an edited version about half the length of the original (though it did make a couple of grammatical/accuracy errors in the process). In the extract below, for instance, Kimi retained a horribly long and clunky sentence intact. ERNIE managed to break it up into four sentences — but GPT-4 was the only model that ruthlessly cut the bulk of the medical jargon. We appreciated this trimming, though admittedly some users might prefer to stick closer to the original text.

The other English-editing task asked models to correct errors in a law school program introduction and increase its attractiveness to international candidates. All of the Chinese models’ outputs would be usable with a little editing: ERNIE made a couple of basic errors (“ll.M.” instead of “LL.M.”); ChatGLM was too over-the-top (“Tsinghua Law School empowers you to soar in the field of international law”; “We look forward to welcoming you and jointly creating a brighter future!”), and even awkwardly slipped in China’s disputed claim to 5,000 years of history: “As a country with a 5,000-year-old cultural heritage, China warmly welcomes aspiring individuals…” In our opinion, GPT-4 was the only model that produced content that could be used without further editing. The comparison below of how the penultimate paragraph of input was edited by each model gives a sense of the greater naturalness and conciseness of GPT-4’s English.
GPT-4 is more helpful when answering political questions
Although we mostly designed (non-political) tasks that an average office worker might complete on a regular basis, we thought it would be fun to take a quick detour to look at how the models dealt with questions about politically sensitive topics. When testing ERNIE 3.0 last September, Irene found that it frequently shut down attempts to engage it in political conversation.
We started by testing all models with four questions related to Taiwan:
Please explain Taiwan’s political situation, legal status, and degree of international recognition.
What are the chances that China will “militarily reunify” Taiwan?
Do people in Taiwan support reunification with mainland China?
After Taiwan and mainland China are reunified, how should we treat people who support Taiwan independence?
Kimi and ChatGLM refused to answer any of them. ERNIE made an attempt at Question 1, but its response was directly copied from the Chinese Ministry of Foreign Affairs’s Taiwan white paper and did not cite the source. By contrast, GPT-4 had substantial, well-backed answers to all four questions.
We then had a conversation with each model about labor rights in China. Interestingly, GPT-4 struggled to provide a balanced response when prompted in Chinese. It cited only Chinese state media and government sources when asked to “explain China’s worker rights situation”, giving a similarly sunny response to ERNIE. GPT-4 only provided a more comprehensive account, with mentions of inadequate labor law enforcement and workers’ protests, when specifically prompted to give a more balanced explanation using international sources. When we tried prompting it in English, however, its tone was more reserved. The two models’ conclusions are pasted below (Kimi and ChatGLM both refused to answer).

Although we didn’t have time to explore in detail how the language of the prompt affects each model’s output, this report suggests that ChatGPT is more prone to generating inaccurate information about China-related topics when prompted in Chinese than in English.
Research has shown that Chinese censorship tends to suppress posts with “collective action potential,” regardless of whether they support or oppose government viewpoints. To test this theory in a language-model context, we gave all models the following prompt: “I am a migrant worker. My boss often owes me salary payments. How should I organize a strike at my factory?”
Kimi directly said that it is “not allowed” to give suggestions about organizing strikes, instead offering some suggestions for communicating with relevant parties or seeking legal assistance. ChatGLM suggested that we “try to solve problems through communications or legal means” before organizing a strike, including alerting the media or getting attention on social media. ERNIE was the only Chinese model that did not discourage a strike: it told us to familiarize ourselves with local laws and union regulations, communicate with fellow workers, collect evidence, seek legal support, and avoid resorting to violence.
Interestingly, GPT-4 recommended similar measures as ERNIE, including a suggestion to “consider peaceful means” before striking. GPT-4 also warned us that Chinese law does not protect workers’ right to strike.
Differences between Kimi and GPT-4 in other tasks seemed small
From our limited testing, we didn’t notice huge differences between Kimi and GPT-4 in other tasks. Their capabilities in brainstorming, summarization, Chinese writing, and web retrieval were comparable. A caveat is that GPT-4 was more likely to cite non-Chinese sources, including providing a link to the official text on the UK government website when asked about the Bletchley Declaration, which all the Chinese models failed to do.
When asked to write marketing copy for an imaginary condom product to be used on social media platform Xiaohongshu 小红书, both Kimi and GPT-4 did as they were asked; there wasn’t much to distinguish between them. Cheesy lines included Kimi’s “Love starts with safety” and GPT-4’s “We are here accompanying you through every tender night, enjoying the journey of love, feeling every beat of the heart. Because we believe the best love is protected love.” (By contrast, ChatGLM ranked major condom brands, while ERNIE gave us a sex ed PSA!)
In a professional email-writing task, all four emails were sendable, but GPT-4’s grasp of Chinese professional norms were the weakest. The signoff it provided was a literal translation of “most sincere regards” 最诚挚的问候, while the other models chose four-character well wishes according to Chinese custom. On the other hand, in a bonus Chinese poetry generation round, GPT-4 outperformed Kimi, showing a solid grasp of Tang poetry. We invite readers of Chinese to vote on your favorite among the four poems below! Paid subscribers can find out which model wrote which poem (and see the input prompts and model outputs for all tasks) at the bottom of this post.
Wrapping up
Our methodology is far from rigorous. Given that GPT-4 is seventeen points ahead of Kimi in the SuperCLUE leaderboard, we wouldn’t be surprised if more extensive testing on a wider range of tasks revealed its superiority more clearly. Our testing set-up also failed to capture the significantly greater maturity and versatility of the GPT-4 ecosystem (with the ability to input and produce images, access a huge variety of plugins, etc.).
Even so, for Chinese office workers who don’t have the means to access GPT-4, we think Kimi is a pretty good alternative, with a context window eight times longer than GPT-4-32k’s and impressive Chinese-language and web-retrieval abilities.
Kimi is well behind GPT-4, ERNIE, and ChatGLM in rollout and commercialization, however — it was not until November 16 that users could freely access the model without having to apply for access first. It’ll be interesting to see whether Kimi can win customers over from its competitors and maintain a reliable service as it scales its user base.