


Scale’s Alex Wang on the US-China AI Race
How to build national moats for AI
How could AI change the global balance of power? What could the US and allies do to preserve national moats?
To discuss, ChinaTalk interviewed CEO of Scale AI, Alex Wang. In a blog post announcing Scale’s $1 billion fundraising success, Alex wrote that Scale is aiming to grow into the world’s data foundry for AI.
Alex grew up in Los Alamos, New Mexico, with two physicist parents who worked in the national labs, and started Scale in college. I am particularly excited to have Alex on the show because maybe the only AI leader in the private sector, who’s been working with the DoD and thinking seriously about the national security implications of AI since before it was cool.
We discuss:
The three key factors limiting rapid AGI takeoff, and how quickly these barriers will be overcome;
China’s strengths and weaknesses in the race for AGI;
National security implications for winning (or losing) the AI race;
Prospects for AI net assessment and the case for a Manhattan project for data;
Methods to prevent AI espionage without kneecapping innovation or profiling immigrants
… and more!
Hitting the Data Wall
Jordan Schneider: We have three factors driving AI progress and ultimately national competitive competitiveness in AI — compute, data, and algorithms. We’ve done a lot of coverage on compute over the past few years in ChinaTalk — with export controls, Chips Act, Huawei chips, and so on — but you’re our first data guest.
Can you give us the 101 on data progress and what needs to happen in order to forge ahead?
Alex Wang: If you were to just zoom all the way out on how AI progress has happened, it’s been through basically three steady exponential curves all stacked on top of one another.
First is the compute curve, both with Moore’s law as well as just the ability to scale such that we can use way more compute than we have in the past.
The second is data. Starting in the early 2010s with the original use of deep learning and neural networks, the amount of data that is used for these algorithms has grown pretty smoothly in an exponential curve. This started with Imagenet, which was a dataset that came out of Fei-Fei Li’s 李飞飞 lab and has basically continued to grow very steadily. The current models are very data-hungry.
The third curve is obviously algorithms, which is the progress of innovation.
The current large language models are trained in two phases — pre-training and post-training. The pre-training phase is what comes to mind naturally for most people. In this phase, you have tens of thousands or hundreds of thousands of GPUs, you get a download of basically the entire Internet, and then you train a huge neural network or a huge transformer-based model on top of all that data.
Out of that process, you get a model that is super smart, but not useful. The way that someone from xAI put this recently is you get an alien, but then you need to get it to do your bidding.
Then the second phase is post-training, where you actually get the model to be optimized for useful functions. This post-training phase depends a lot on expert data, or what we call frontier data. This is where you commonly apply techniques like RLHF (Reinforcement learning from human feedback), and SFT (supervised fine-tuning). Here, you leverage exquisite, high-quality data to build these models such that they perform dramatically better at very useful problems like coding.
This is where a lot of the safety controls come into place. The second phase of post-training is where most of the progress has come over the past two years. This is well known in the industry, but maybe not so well known everywhere else, since GPT four was originally trained in the fall of 2022, we actually haven’t yet had a pre-train that massively outperforms GPT-4. All of the progress since then has been through this post-training process. This is quite stark.
GPT-3.5 today is better than GPT-4 was when it first came out because of this overall post-training process.
You can overcome a lot of performance limitations through great post-training. This is where we’ve started to see, models that can do bold code analysis, run code on their own, do more advanced agent tasks, and start to automate various kinds of work.
Jordan Schneider: Is there a ceiling on what can be accomplished with post-training?
Alex Wang: There are conflicting answers in the research community right now. Honestly, it’s one of the biggest questions in the field. Some believe that post-training is just exposing a lot of the intelligence that already exists in the model. Thus, post-training cannot give a model new skills if it lacks intrinsic capabilities.
But then there’s this alternate belief, which seems to have played out more so far, that we might be able to get a huge chunk of the way toward AGI just with post-training GPT-4.
Recent developments surrounding QStar and others indicate that AI systems are getting pretty close to solving International Mathematics Olympiad-level problems
If we can post-train GPT-4 to solve graduate-level math problems, then it probably has a lot of the intrinsic capability and intelligence to be able to do almost anything that a human can do.
But this is a hotly debated topic in the industry.
Jordan Schneider: How far can you get with clever algorithmic QStar? Where do the datasets from Scale AI come in?
Alex Wang: One of the bitter lessons of AI writ large is that you are fundamentally bottlenecked by the data that you have to train these models on. No matter what you do, you can’t overcome the fundamental limitations of a lack of data. Nearly any capability that you want to train requires data that reflects those capabilities. This is one of the core problems in post-training — for a lot of the problems that we want these models to solve, the data is not recorded or does not exist.
If I want a model that is able to do the job of a financial analyst — you can get analysts’ Excel models, but you can’t access most of the thinking that goes on in their head. Most of the reasoning is not meaningfully recorded in any current dataset. Nearly all post-training capability upgrades require some amount of frontier data.
Frontier data includes things like agent behavior chains. It’s reasoning data and decision chains from the world’s experts. It’s complex code data, complex math, or other STEM data.
That’s really the data that’s missing. Then there’s a question of how much data from human expertise is required, versus synthetically generated data. The verdict here is that you need a mixture. It requires hefty collaboration between AI models and the world’s best and brightest minds to produce as much of that data as possible.
Jordan Schneider: For a national security analogy — the type of expert data you’re referencing is like a fighter pilot looking at a video of what's around them and saying, “I would turn left at 32 degrees,” or an intelligence analyst being shown five pieces of intel and saying, “I think there’s something here because I have 30 years of experience and I know how the Taliban think.”
If you take thousands of those data points and feed them into a model with base intelligence, then all of a sudden that model becomes 50-100% better for a particular use case. Is that accurate?
Alex Wang: Exactly. My personal thesis is that this process will be the hardest part of making AI a fundamental game changer.
Jordan Schneider: It sounds like we’ll need to expend a lot of labor to make these big, exquisite, handcrafted data sets, in addition to making a bunch of synthetic data. Do you think we need a national moat for something like that?
Alex Wang: Let me set the stage by defining the industry term “data wall.” Simply put, this is the realization that we’ve used almost all the data on the Internet, and the Internet produces new data extremely slowly. We’ve run into the data wall because we've used data that's been captured over the course of decades, but we're not producing new data all that quickly.
A lot of how the future of AI progress plays out boils down to how well can we scale this data wall and how we can move beyond it. The general philosophy is that we need data abundance. In the same way that we are pushing through a lot of the constraints on the supply chain for chips, we need to push through a lot of the constraints on the supply chain for data, and we need to build the means of production for huge amounts of data.
There are multiple approaches to this. The first is to focus on quality. You produce the most exquisite, high-end expert datasets — frontier data, as we call it — and you figure out a process to produce that data en masse.
Other methods include building synthetic environments for these models. This would be a game-like environment where the models can interact with themselves and learn through reinforcement. These environments need to be built by human experts and by the best and brightest people in the world. There’s no free lunch in terms of their involvement in this process.
The final method is synthetic data. These methods aren’t bad, but by and large, synthetic data is a one-time bump on top of all of your preexisting real data. Maybe you can take your preexisting data and triple the quantity with synthetic data, but at some point, you’re repeating things over and over again. You’re not getting new information content, and it doesn’t improve the model dramatically more than that.
At the end of the day, we are fundamentally bottlenecked by the production of frontier data, as well as the production of these self-play environments for reinforcement-based learning.
Chinese Espionage and the Race to AGI
Jordan Schneider: Less than 1% of Chat-GPT’s training data was in Mandarin, and it’s 98% as smart and Mandarin as it is in English. When you see quotes from the heads of the Chinese labs, they’re not stressed about the fact that common crawl is mostly in English because they can just suck out the intelligence and then translate to Mandarin easily.
My real question is — if we presume that industrial espionage is going to target AI, and that there are plenty of smart Chinese PhDs and fighter pilots and intel analysts who can make exquisite data — then how can the US develop a long-term, sustainable data advantage?
Alex Wang: There’s reason for optimism. The United States is charismatic as a destination for top talent. The best and brightest people in the world want to emigrate to the USA. If we can keep that up, the United States will have a fundamental advantage in the sort of expert capabilities, expert knowledge, and exquisite talents that will power these frontier datasets.
In general, I’m quite bullish on American innovation. But the issue of tech espionage is a fundamental spoiler for all US development.
If we're in a world where all cutting-edge AI development is happening in private labs where all the secrets get stolen, then you’re screwed. There’s no chance of building a national advantage under those circumstances.
Jordan Schneider: Scientists who contribute these data sets will essentially be putting their brains into the cloud to create better intelligence for everyone.
But that turns their intellectual excellence into bits and bytes, and bits and bytes are so much easier to steal than physical machinery like a fab. If nation-state actors pour their resources into getting these datasets, will there be any secret sauce that is abstracted and implicit to the software itself, such that it can’t be stolen as easily as data?
Alex Wang: This is really important — the models themselves are bits and bytes. At the end of the entire process, when you run them on a huge data center, when you use all the data in the world, it boils down to a file of weights. Those model weights are bits and bytes that can be stolen.
The current levels of lab security are truly not conducive to keeping these weights secret. For example, look to the recent arrest of the Google engineer Leon Ding 丁林葳. He was working on AI infrastructure at Google. He stole the TPU v6 design and a bunch of training code, among other things.

All he had to do was copy-paste all the code into Apple Notes, export from Apple Notes to PDF, and walk out the door.
The levels of security that are required to actually prevent all the stuff from being stolen are much, much higher than where we have today.
Jordan Schneider: It says a lot that someone using such stupid tactics for industrial espionage only got caught after the fact.
I went to NeurIPS for the first time last year, and I was blown away by how much Mandarin was being spoken by people with American affiliations.
I have a good friend of mine who’s Chinese American. We’re on a call with some people from the government, and as soon as he turns the camera on, the first thing he says is, “I’m a US citizen, and I used to work in the Department of Commerce.”
That broke my heart! I asked about it afterward, and he said to me, “Jordan, I have to do that every single time. Otherwise, the conversations end after seven minutes.”
Care to reflect on the balance of wanting to attract the world’s best talent while at the same time sort of dealing with latent espionage issues?
Alex Wang: These are issues that I’ve personally had to overcome as well. I have lots of meetings with folks in the government. Looking the way I do, I have to preface myself and overcome these implicit biases that people have.
Jordan Schneider: Well, let’s stay on that for a second. Tell me how you really feel, Alex.
Alex Wang: Well, to be clear, my parents immigrated from China to the US. They hate the CCP, and they worked on national security problems in the United States.
I grew up in Los Alamos, New Mexico, very passionate about national security and passionate about defending America. Yet, to your point, it is like this tax in every interaction. I have to preface with, “Hey, I was born in Los Alamos. I grew up in Los Alamos. My parents are dedicated civil servants. I want to make sure that the United States will win in AI.”
I’ve been lucky that actually there have been a number of champions of mine and a number of people within the government who understand that and have put me in positions and put Scale in positions to have a real impact.
For that, I’m grateful. But this is a real issue or a real question.
If you zoom out — by and large, this is a one-way road. Talent leaves China, comes to America, and they don’t go back to China. Most people leaving China dislike the CCP, and so really don’t intend to move back.
You see this in some of even China’s sort of policies or sort of some of the ways that they’ve been managing their populations.
It used to be that they would encourage folks to come to the US for grad school, but then they noticed that not enough people come back. Now they encourage them to go to Russia or Europe.
I’m not going to start harping on this because — as it currently stands, we are not in a good situation.
As it currently stands, with the current structure of these private AI labs with minimal security, there’s no way that the United States will win.
But if we solve that problem, if we’re in a world where we can have confidence in the security of our AI efforts, then we should be trying to take in as much high-end talent from China as possible, because the reality is China is churning out more high-end STEM talent than anywhere else in the world.
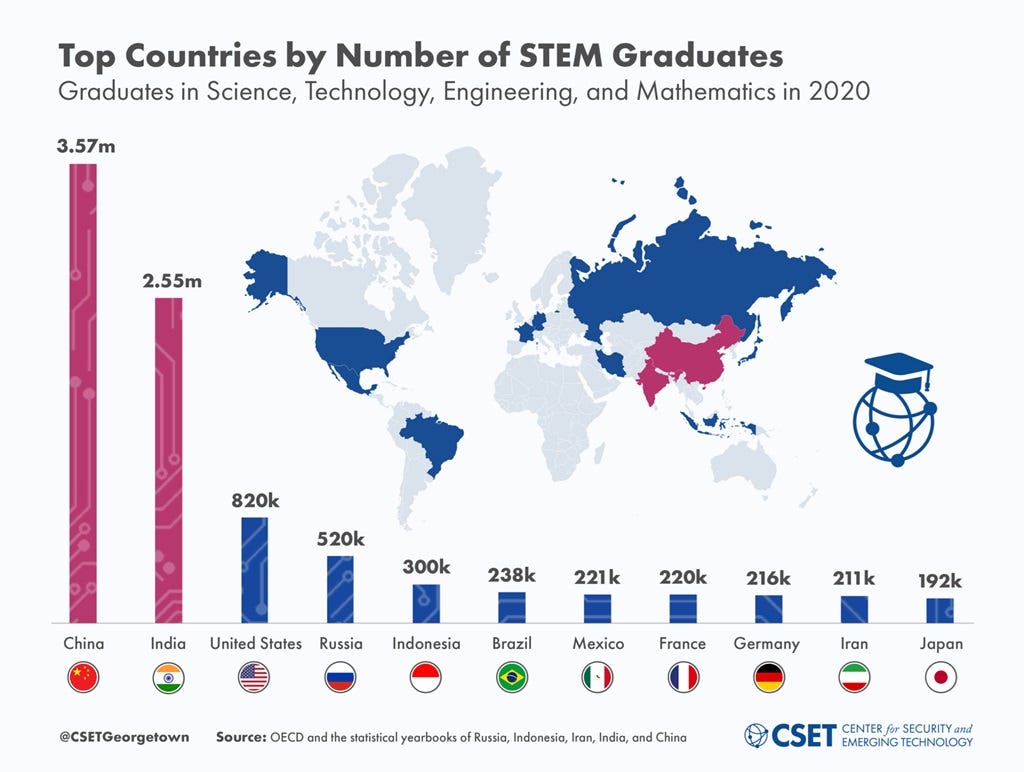
Jordan Schneider: People really misunderstand China’s immigration policies. The Thousand Talents Program is cope! The Chinese system understands and acknowledges that China is not attracting people naturally. These programs have to promise ridiculous salaries, which they only pay out for a couple of months of course.
It also breaks my heart to see news reports about TSA agents harassing PhD students who happen to be Chinese nationals.
The long-term impact of that news story — even if it’s just ten Tsinghua graduates who decide to stay in China because they fear immigration bullshit — is way bigger than the random hunch of some border agent.
Takeoff speed and the AI arms race
Jordan Schneider: We’re going to cross our fingers that you’re going to make some great data sets, and that our labs come up with some brilliant algorithms, and maybe they’ll do a better job of keeping the secrets.
But if not, there seem to be two other things that might give you that long-term advantage, both for economic growth more broadly as well as the national security-specific stuff.
One is compute. If you just have bigger data centers and badder chips, then you can deploy this stuff at a larger level.
Then there’s this more amorphous, broader question of AI diffusion. How are companies, individuals, schools, governments, and hospitals going to grok this stuff? Are people in general going to accept it?
Alex Wang: For the purposes of your question, there are two different types of AI diffusion — commercial and military.
I predict that economic diffusion within businesses will happen reasonably quickly, but still way slower than most people expect.
The forces of capitalism will force companies to adopt. If some companies can gain a meaningful edge from AI implementation, they’ll be able to disrupt their competitors. Competitive pressures will force companies to adopt relatively quickly.
The best example of this is Apple’s recent announcement about Apple Intelligence.
Most of the reporting said that Apple was very behind on AI, and thus had to lean on OpenAI. But because they needed a strong AI story, they actually developed a very smart framework for how to integrate AI into all their products.
They’re integrating AI as a core part of the OS in a deeper way than anyone else. Tons of Americans have Apple devices. This is going to diffuse through the economy incredibly quickly, as far as tech diffusion goes. But it isn’t as though we’ll snap our fingers and suddenly AI will be everywhere.
The national security AI diffusion is happening incredibly slowly. I have very little optimism that this changes meaningfully without some real glass being broken. There are a few reasons for this. National security enterprises are risk-averse.
There’s less of an understanding that this is such a critical issue unless there’s a problem that pushes us to think about it deeply. Then there are all these sclerotic processes with federal budgeting for new programs, procurement, showing results, and then lobbying Congress for more funding.
It’s not even clear if the diffusion through national security would ever keep up with the development in the commercial sector.
Jordan Schneider: That makes sense. If you can’t count on American capitalism to push a big technological change into society broadly, then we might as well just give up. But on the government side, we just had House Majority Leader Steve Scalise saying he wouldn’t support legislation that sets up new agencies, establishes licensing requirements, or spends money on research and development that favors one technology over the other.
On the one hand, you can sit back and let Apple compete with Google to make the best AI phone, but you can’t sit back and hope that the national security state or the Department of Education or the Department of Health and Human Services, gets AI into their infrastructure, because there’s no competitive pressure on a lot of these organizations.
Alex Wang: Exactly. The critical job of the US government is national security. To the degree that you think that AI is a military technology, which it almost certainly is, then the United States government has an imperative to be competitive and frankly, lead on AI. They can’t just be passive and let it play out in the private sector. That does nothing to help the United States government fulfill its mission of providing national security.
It’s quite frustrating. The United States government needs to spend money to ensure that we are investing, to ultimately lead on AI for national security purposes. and this is very much a global adversarial scenario. We need to think deeply about where our competitors are, what they care about, and what they are going to do with AI technology.
For less nebulous technologies, we usually wait until we’ve been surpassed before we get our act together.
You can see this with hypersonic missiles, as well as a lot of developments in space technology — we’ve waited for China to catch up a little bit before reigniting the flames.
I have a real concern that it will take a crisis to make us take this stuff seriously.
AI Tech Net Assessment
Jordan Schneider: I bang the drum on this a lot as well. It’s literally me, Jeff Ding, Matt Sheehan, and a few other people who are focused on watching China’s algorithmic progress and data center build-outs. The question of what China is doing to help, or hinder, its firms in creating these types of datasets seems crucially important.
This is a wild card for the future. The government should want to know what’s happening in the private sector as well as what’s going on in adversary countries. By the way, if you take a look at models like SuperCLUE and Chatbot Arena, then you can see that the Chinese models are basically as good as the American ones. We need to invest in understanding what’s going on there.
Alex Wang: We’re of one mind on this. It’s totally crazy.
Jordan Schneider: Can you explain your perspective on the Chinese AI ecosystem? What kind of data should we look at in order to get a holistic understanding of their capabilities?
Alex Wang: The first indicator is the quality of Chinese chips versus Nvidia chips. The most up-to-date stat here is that the Huawei Ascend 910B, which is manufactured on SMIC fabs, is about 80% as good and two to three times more costly than Nvidia chips in terms of performance per dollar. But roughly speaking, these are in the ballpark to be competitive. The SMIC fabs have seven-nanometer capabilities, vs two to three-nanometer capabilities for TSMC, but that might be fine. Figuring out the capability levels requires continuous experimentation.
The second indicator is just the production levels. Huawei is manufacturing something like 100,000 chips per quarter versus roughly a million chips per quarter for Nvidia. We need to track that ratio very tightly. Once that ratio gets within, let’s say, three to one, we need to be concerned.
Another indicator is power. We need to be measuring new power generation in the US versus China very closely, because the real bottleneck in the medium timeframe is power rather than the actual chips.
China is adding way more power than the United States. We need to reignite our power growth. In China, they can very easily add a lot more nuclear power than is politically feasible in the United States. We need to take that pretty seriously as a disadvantage.
In terms of data, the key thing to pay attention to within China is how they are utilizing data from the internet and overseas. In the US, we’re going to litigate a lot of the rights around data and the ability to use data for training these models. It’s unlikely those get litigated in China. We just need to track exactly how that debate on data usage plays out in China.
China has this concept of data factories where they take citizens of China to produce data for AI models. They did this for their facial recognition efforts and their self-driving car efforts in the last era of AI.

We need to track those data factories, including looking at how many people are going into them.
Then the last piece is algorithmic development. They will not publish all the models they produce. We shouldn’t expect that. But we generally want to observe what the scaling laws of the Chinese models are. The base assumption should be that they're going to be behind us meaningfully on scaling law.
Every doubling of compute expenditure for China is not going to be as productive as every doubling of compute expenditure in the United States.
But we need to have a competitive intelligence team very closely monitor the various sized models and various amounts of compute that go into these models to understand those scaling laws.
Jordan Schneider: Let’s talk a little bit about sort of like the hard takeoff versus slow or takeoff scenario, right? We just had Leopold Aschenbrenner, who dropped the mega four-and-a-half-hour podcast and 200-page PDF that somehow Donald Trump seems like he listened to.
We have to be at the forefront. It’s gonna happen, and if it’s gonna happen, we have to take the lead over China.
China is the primary threat in terms of that, and you know, what they need more than anything else is electricity. They have to have electricity, massive amounts of electricity. I don’t know if you know that.
In order to do these, essentially, it’s a plant, and the electricity needs are greater than anything we’ve ever needed before to do AI At the highest level and China will produce it because they’ll do whatever you have to do, whereas we have environmental impact people and you know, we have a lot of people trying to hold us back. Massive amounts of electricity are needed in order to do AI and we’re gonna have to generate a whole different level of energy.
Where do you fall on this, Alex? Just how much better can AI get over the next three to five years?
Alex Wang: I don’t think there’s any scenario where we just hit like some really big wall and AI is doomed forever, but there the data wall is real.
We need to be innovative in scaling that data wall. It relies on human innovation, algorithmic improvement, and data production.
I personally place a lower probability on these fast takeoff scenarios. Leopold believes in AGI by 2027. I personally place a lower probability mass on that, but it is in the realm of possibility, so you have to take that outcome very seriously.
You need all the pillars to come up together — compute capabilities, data production capability, and algorithmic capabilities. I believe making all of those come together is going to take a little bit longer than we expect, but not dramatically longer.
Scale got started in the autonomous vehicle industry. A decade ago, there were a lot of people who said there would be full self-driving cars in two years. They would keep saying that every year, until people stopped believing them. There was a huge crash in the market, but the firms continued to work on this problem.
Now, there are actual Level 4 autonomous self-driving vehicles in San Francisco, in LA, and in Phoenix from Waymo. It just took 10 years instead of two years like everyone was promising.
That’s generally where my head is at. It’s going to take a little bit longer than people are saying now. But it’s not going to take 100 years. This is a technology that is going to happen and we need to be prepared for it.
Jordan Schneider: Let’s play Sci-Fi for a little bit. Pretending that you assign a higher probability to the Leopold world — what would you be different doing differently at your company? What would you have the labs do? What would you tell policymakers to batten down the hatches and get ready for?
Alex Wang: Leopold is a good friend, and he games this stuff out pretty well.
If you believe we are on this fast takeoff scenario and that we’re imminently close to AGI — then you need to prevent all of our secrets from going over to our adversaries and you need to lock down the labs.
There are a lot of ways you can do that. You could have a government agency that’s responsible for security among all the labs. I grew up in Los Alamos, so I’m partial to government labs. Maybe there could be a government lab that sort of serves as a parent organization to all the sub-labs.
You have to accept by definition that that’s going to slow some of the deployment for economic gains. Once you deploy this stuff for economic reasons, you’re also deploying it to be stolen by our adversaries.
Next, the DoD, the intelligence community, and the national security community need to immediately take this incredibly, incredibly seriously. I wrote about this a few years ago.
It doesn’t take a lot of imagination to realize that powerful AI systems, if they existed, would be a definitive military technology.
You could imagine that nuclear deterrence doesn’t even really matter in a world where you have advanced AI systems.
They can do superhuman hacking. They enable autonomous drone swarms. They can give you full situational awareness, they can develop biological weapons.
You can diffuse and perhaps neutralize an enemy’s nuclear arsenal.
Everyone within the national security community in the United States needs to understand, grok, and pay attention. This is a Manhattan project-level of technological capability. Then you have to invest in the inputs. You need to make huge investments into chips, and even bigger investments into power.
Over the last decade, China added a quantity of energy to their grid that is equivalent to the entire US power grid.
The US, by comparison, is relatively stagnant.
You also need big investments in data. You probably need to coalesce the academic community in the USA into some sort of frontier data foundry to sort of build this sort of data advantage. Then you need to believe in American research capabilities and American innovation to lead on algorithms, which I believe will be the default outcome.
If you look at the best Chinese models, they’re basically carbon copies of American models, which is why I say that the US leading is the default path.
Jordan Schneider: Let’s discuss your call to action for the national security community. I’m sure you’ve explained this in hundreds of meetings so far. Who understands this and who doesn’t?
Alex Wang: An understanding of history is pretty critical. People who have studied military history and understand just how irrevocably war has changed since the 1850s— they get it.
Then you get into quibbles around whether AI is really “all that” as a technology, as opposed to just a dumb chatbot. That’s more of a quibble in my mind when you actually sort of demonstrate some of the things that it can do.
Jordan Schneider: What’s your top-ten policy wish list to unlock the good stuff?
Alex Wang: We can leverage the fact that we truly do have a coalescence of many of the brightest PhDs in the world.
We need some program by which they can effectively volunteer their expertise to a national AI data repository. Then in a sharp takeoff scenario or a lead-up to AGI, maybe some of it gets drafted. It can be used by a mixture of the leading labs in the United States as well as the academic institutions themselves, so that they can do their own advanced AI research.
People have asked me — how can the academic community actually contribute to AI if they don’t have access to huge amounts of chips? Well, this is the answer.
The key is leveraging the human capital that we have in America to drive forward progress in AI for biology, chemistry, physics, fusion simulations, and everything else.
Philanthropy and the Tea Routine of Champions
Jordan Schneider: Jack Ma recently defended the 996 lifestyle by saying, “Look, if you’re not working hard, you’re not going to get that foundation money.”
Alex, have you thought about how you’d want to be philanthropic one day?
Alex Wang: There are a few things that are really important. One is STEM education, and there are a few ways to influence this globally. There are a number of people who have had a real impact.
I met the person who runs code.org, which has enabled a huge amount of computer science education for young people globally. Quality STEM education is the number one input to the pace of human progress.
My other interests are centered around ensuring American competitiveness.
There’s a lot of low-hanging fruit both from a national security standpoint as well as from a technological standpoint. One of the things that I tell people when I visit DC — Scale is a company, we don’t have to do anything for national security. In many ways, it is far easier to grow a business outside of the national security world. It would be far easier for us to focus on customers in the private sector.
We made a decision to invest a very meaningful portion of our resources towards developing AI capabilities for the national security community and for the US government.
That’s because we believe it is one of these problems that is disproportionately important relative to what the market might assign to it.
Jordan Schneider: Speaking of STEM education, what can math teach you about how to be a CEO?
Alex Wang: On some level, running a business is just lots and lots of problem-solving. You have to devise solutions to these problems. Core problem solving is the skill that math teaches you, along with how to be very rigorous about solutions to these problems.
Math teaches you that there are a lot of different ways to approach a problem. Maybe you need to break it down and learn more about the problem before you’re able to solve it.
That is the transferable skill. The deeply nontransferable skill is that — math makes sense. You’re not going to hit situations that just don’t make any sense. Human systems, not so much.
There are all sorts of things that are not logically consistent about both how people operate, but also just how a large human system will operate. Bureaucracy is one of these things. Bureaucracy is just an emergent property of lots and lots of people working on things together.
One of the key components of being successful in business is having conviction in the face of things that don’t make sense. You need to figure out ways to blow past them or resolve those issues. Math doesn't really teach you how to do that.
Jordan Schneider: Final question — why is tea superior to coffee, and what is your tea tier list?
Alex Wang: The key thing is that tea lets you titrate your caffeine consumption much more granularly. When people end up drinking coffee, they’re just overwhelming their system with huge amounts of caffeine, whereas different teas have different caffeine levels. If you pick your teas correctly, you can actually get a smooth onset amount of caffeine that lets you do the work that you need to without having major crashes. Also, the variety of tea flavor profiles is just far greater than the variety in coffee. I, for one, want to live in a world of constantly new discoveries and new experiences.
I really like Japanese and Chinese teas. I usually start my day with a pu’er tea, then around midday maybe I’ll have a jasmine green tea or something like that. At the end of the day, maybe I’ll have a Hōjicha or a sobacha.
