
What It Takes to Compete in AI with the Latent Space Podcast
How innovations diffuse across national boundaries
Frontier AI models, what does it take to train and deploy them? How difficult is it to “fast follow”? What are the medium-term prospects for Chinese labs to catch up and surpass the likes of Anthropic, Google, and OpenAI?
To discuss, I have two guests from a podcast that has taught me a ton of engineering over the past few months, Alessio Fanelli and Shawn Wang from the Latent Space podcast. Alesio runs a venture capital firm called Decibel, and Shawn runs a firm called smol.ai. Both Dylan Patel and I agree that their show might be the best AI podcast around.
In this episode we discuss:
The secret sauce that lets frontier AI diffuses from top lab into Substacks.
How labs are managing the cultural shift from quasi-academic outfits to firms that need to turn a profit.
How open source raises the global AI standard, but why there’s likely to always be a gap between closed and open-source models.
China’s status as a “GPU-poor” nation.
Three key algorithmic innovations that could reshape the balance of power between the “GPU rich” and “GPU poor.”
, Italian, probably Urbino")
What Makes Frontier AI?
Jordan Schneider: Let’s start off by talking through the ingredients that are necessary to train a frontier model.
Shawn Wang: At the very, very basic level, you need data and you need GPUs. You also need talented people to operate them.
Jordan Schneider: Let’s do the most basic. Let’s go from easy to complicated. Say all I want to do is take what’s open source and maybe tweak it a little bit for my particular firm, or use case, or language, or what have you. What’s involved in riding on the coattails of LLaMA and co.?
Shawn Wang: I would say the leading open-source models are LLaMA and Mistral, and both of them are very popular bases for creating a leading open-source model. This would not make you a frontier model, as it’s typically defined, but it can make you lead in terms of the open-source benchmarks.
Typically, what you would need is some understanding of how to fine-tune those open source-models. Those are readily available, even the mixture of experts (MoE) models are readily available. And then there are some fine-tuned data sets, whether it’s synthetic data sets or data sets that you’ve collected from some proprietary source somewhere. That’s definitely the way that you start.
Alessio Fanelli:
The biggest thing about frontier is you have to ask, what’s the frontier you’re trying to conquer?
OpenAI, DeepMind, these are all labs that are working towards AGI, I would say. That’s the end goal.
It’s one model that does everything really well and it’s amazing and all these different things, and gets closer and closer to human intelligence.
The open-source world, so far, has more been about the “GPU poors.” So if you don’t have a lot of GPUs, but you still want to get business value from AI, how can you do that? That’s a whole different set of problems than getting to AGI. A lot of times, it’s cheaper to solve those problems because you don’t need a lot of GPUs.
Sometimes, you need maybe data that is very unique to a specific domain. Or you might need a different product wrapper around the AI model that the larger labs are not interested in building.
The market is bifurcating right now. The open-source world has been really great at helping companies taking some of these models that are not as capable as GPT-4, but in a very narrow domain with very specific and unique data to yourself, you can make them better.
Data is definitely at the core of it now that LLaMA and Mistral — it’s like a GPU donation to the public. These models have been trained by Meta and by Mistral. Now you don’t have to spend the $20 million of GPU compute to do it. You can only spend a thousand dollars together or on MosaicML to do fine tuning. All of a sudden, the math really changes.
But, the data is important. But, if you want to build a model better than GPT-4, you need a lot of money, you need a lot of compute, you need a lot of data, you need a lot of smart people. You need a lot of everything.
That’s a much harder task.
Open Source vs Frontier Models
Jordan Schneider: One of the ways I’ve thought about conceptualizing the Chinese predicament — maybe not today, but in perhaps 2026/2027 — is a nation of GPU poors.
If the export controls end up playing out the way that the Biden administration hopes they do, then you may channel an entire country and multiple enormous billion-dollar startups and firms into going down these development paths.
They are not necessarily the sexiest thing from a “creating God” perspective. But they end up continuing to only lag a few months or years behind what’s happening in the leading Western labs.
A few questions follow from that. What are the mental models or frameworks you use to think about the gap between what’s available in open source plus fine-tuning as opposed to what the leading labs produce? What is driving that gap and how may you expect that to play out over time?
Shawn Wang:
The sad thing is as time passes we know less and less about what the big labs are doing because they don’t tell us, at all. We don’t know the size of GPT-4 even today.
We have some rumors and hints as to the architecture, just because people talk. And one of our podcast’s early claims to fame was having George Hotz, where he leaked the GPT-4 mixture of expert details.
But it’s very hard to compare Gemini versus GPT-4 versus Claude just because we don’t know the architecture of any of those things. And it’s all sort of closed-door research now, as these things become more and more valuable.
That said, I do think that the large labs are all pursuing step-change differences in model architecture that are going to really make a difference. Whereas, the GPU poors are typically pursuing more incremental changes based on techniques that are known to work, that would improve the state-of-the-art open-source models a moderate amount.
To date, even though GPT-4 finished training in August 2022, there is still no open-source model that even comes close to the original GPT-4, much less the November 6th GPT-4 Turbo that was released. That is even better than GPT-4. The closed models are well ahead of the open-source models and the gap is widening.
We can talk about speculations about what the big model labs are doing. We can also talk about what some of the Chinese companies are doing as well, which are pretty interesting from my point of view. But those seem more incremental versus what the big labs are likely to do in terms of the big leaps in AI progress that we’re going to likely see this year.
Alessio Fanelli: Yeah. And I think the other big thing about open source is retaining momentum. So a lot of open-source work is things that you can get out quickly that get interest and get more people looped into contributing to them versus a lot of the labs do work that is maybe less applicable in the short term that hopefully turns into a breakthrough later on.
So you can have different incentives. Therefore, it’s going to be hard to get open source to build a better model than GPT-4, just because there’s so many things that go into it. You can only figure those things out if you take a long time just experimenting and trying out.

Loose Lips, Nerd Parties, & Frontier AI
Jordan Schneider: This idea of architecture innovation in a world in which people don’t publish their findings is a really interesting one.
One of the key questions is to what extent that knowledge will end up staying secret, both at a Western firm competition level, as well as a China versus the rest of the world’s labs level.
I’m curious, before we go into the architectures themselves. How does the knowledge of what the frontier labs are doing — even though they’re not publishing — end up leaking out into the broader ether?
Shawn Wang:
Yeah, honestly, just San Francisco parties. People just get together and talk because they went to school together or they worked together.
OpenAI does layoffs. I don’t know if people know that. They just did a fairly big one in January, where some people left.
Just through that natural attrition — people leave all the time, whether it’s by choice or not by choice, and then they talk.
They do take knowledge with them and, California is a non-compete state. You can’t violate IP, but you can take with you the knowledge that you gained working at a company. That does diffuse knowledge quite a bit between all the big labs — between Google, OpenAI, Anthropic, whatever. And so, I expect that is informally how things diffuse.
More formally, people do publish some papers. OpenAI has provided some detail on DALL-E 3 and GPT-4 Vision. That was surprising because they’re not as open on the language model stuff. DeepMind continues to publish quite a lot of papers on everything they do, except they don’t publish the models, so you can’t really try them out. You can go down the list in terms of Anthropic publishing a lot of interpretability research, but nothing on Claude.
You can go down the list and bet on the diffusion of knowledge through humans — natural attrition. There’s a fair amount of discussion.
You can see these ideas pop up in open source where they try to — if people hear about a good idea, they try to whitewash it and then brand it as their own. There’s a very prominent example with Upstage AI last December, where they took an idea that had been in the air, applied their own name on it, and then published it on paper, claiming that idea as their own. And there’s just a little bit of a hoo-ha around attribution and stuff.
But, if an idea is valuable, it’ll find its way out just because everyone’s going to be talking about it in that really small community. Sometimes it will be in its original form, and sometimes it will be in a different new form.
Jordan Schneider: Is that directional knowledge enough to get you most of the way there? Where does the know-how and the experience of actually having worked on these models in the past play into being able to unlock the benefits of whatever architectural innovation is coming down the pipeline or seems promising within one of the major labs?
Alessio Fanelli: I would say, a lot. Also, when we talk about some of these innovations, you need to actually have a model running. So if you think about mixture of experts, if you look at the Mistral MoE model, which is 8x7 billion parameters, heads, you need about 80 gigabytes of VRAM to run it, which is the largest H100 out there. If you’re trying to do that on GPT-4, which is a 220 billion heads, you need 3.5 terabytes of VRAM, which is 43 H100s.
You need people that are algorithm experts, but then you also need people that are system engineering experts.
You need people that are hardware experts to actually run these clusters.
The know-how is across a lot of things. You might even have people living at OpenAI that have unique ideas, but don’t actually have the rest of the stack to help them put it into use. Because they can’t actually get some of these clusters to run it at that scale.
The other example that you can think of is Anthropic. The founders of Anthropic used to work at OpenAI and, if you look at Claude, Claude is definitely on GPT-3.5 level as far as performance, but they couldn’t get to GPT-4. There’s already a gap there and they hadn’t been away from OpenAI for that long before. This learning is really quick.
Versus if you look at Mistral, the Mistral team came out of Meta and they were some of the authors on the LLaMA paper. Their model is better than LLaMA on a parameter-by-parameter basis. They had obviously some unique knowledge to themselves that they brought with them. It’s on a case-to-case basis depending on where your impact was at the previous firm.
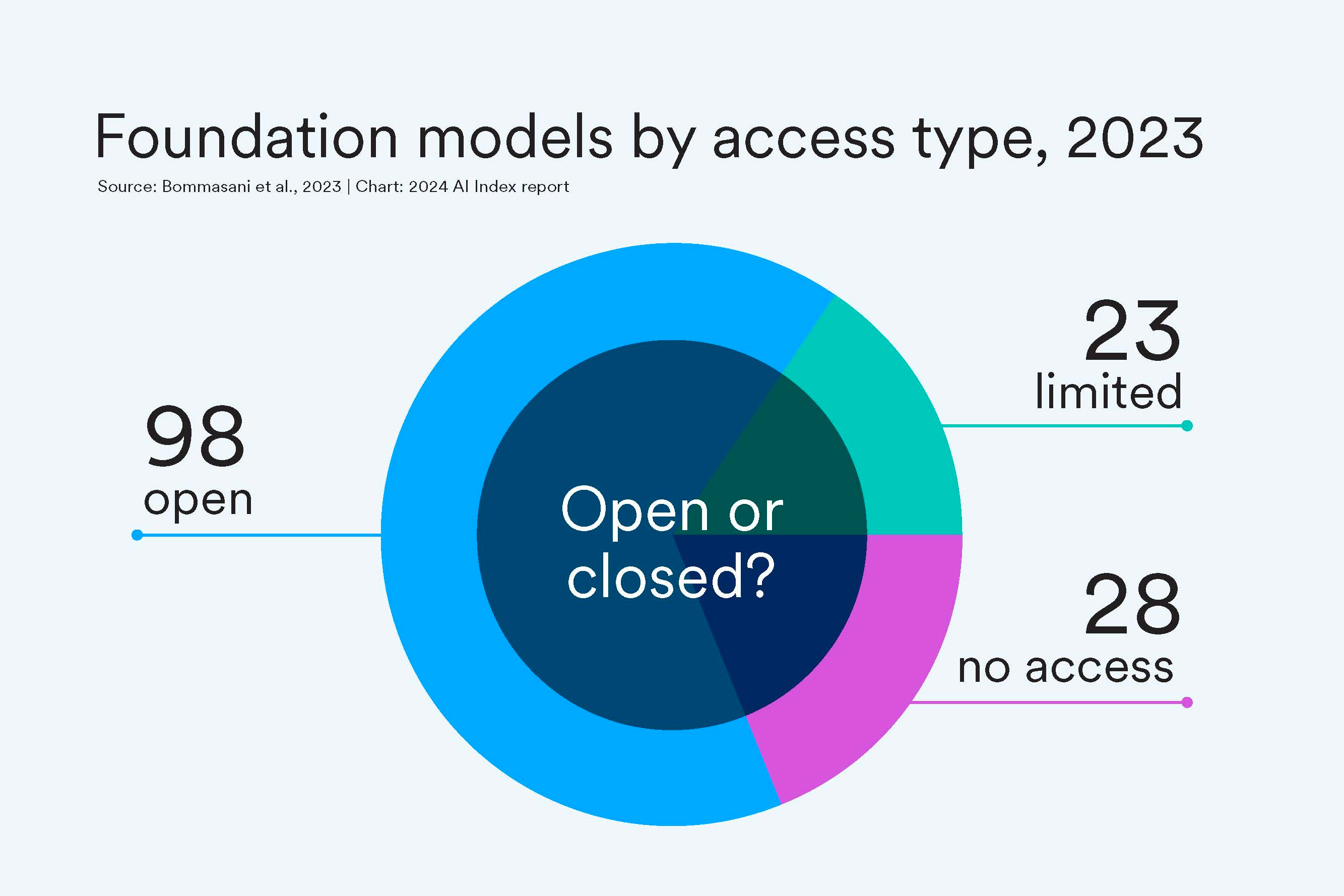
Seeing Open Source Like a State
Jordan Schneider: This is the big question. Say a state actor hacks the GPT-4 weights and gets to read all of OpenAI’s emails for a few months. Is that all you need? To what extent is there also tacit knowledge, and the architecture already running, and this, that, and the other thing, in order to be able to run as fast as them?
Shawn Wang: Oh, for sure, a bunch of architecture that’s encoded in there that’s not going to be in the emails. It depends on what degree opponent you’re assuming. If talking about weights, weights you can publish right away. Just weights alone doesn’t do it. You have to have the code that matches it up and sometimes you can reconstruct it from the weights. Sometimes, you cannot.
But let’s just assume that you can steal GPT-4 right away. Then, going to the level of communication. Then, going to the level of tacit knowledge and infrastructure that is running. And I do think that the level of infrastructure for training extremely large models, like we’re likely to be talking trillion-parameter models this year.
Those extremely large models are going to be very proprietary and a collection of hard-won expertise to do with managing distributed GPU clusters.
Particularly that might be very specific to their setup, like what OpenAI has with Microsoft. That Microsoft effectively built an entire data center, out in Austin, for OpenAI.
I’m not sure how much of that you can steal without also stealing the infrastructure.
Alessio Fanelli: I think, in a way, you’ve seen some of this discussion with the semiconductor boom and the USSR and Zelenograd.
You can obviously copy a lot of the end product, but it’s hard to copy the process that takes you to it. Then, once you’re done with the process, you very quickly fall behind again.
If you got the GPT-4 weights, again like Shawn Wang said, the model was trained two years ago. So you’re already two years behind once you’ve figured out how to run it, which is not even that easy. So that’s really the hard part about it.
And software moves so quickly that in a way it’s good because you don’t have all the machinery to construct. But, at the same time, this is the first time when software has actually been really bound by hardware probably in the last 20–30 years.
Even getting GPT-4, you probably couldn’t serve more than 50,000 customers, I don’t know, 30,000 customers? There’s just not that many GPUs available for you to buy. That’s the other part. It’s like, academically, you could maybe run it, but you cannot compete with OpenAI because you cannot serve it at the same rate.
Jordan Schneider: It’s really interesting, thinking about the challenges from an industrial espionage perspective comparing across different industries. Because you’ve seen a fair amount of success with Huawei and routers back in the ’90s and 2000s.
But you had more mixed success when it comes to stuff like jet engines and aerospace where there’s a lot of tacit knowledge in there and building out everything that goes into manufacturing something that’s as fine-tuned as a jet engine.
It’s a really interesting contrast between on the one hand, it’s software, you can just download it, but also you can’t just download it because you’re training these new models and you have to deploy them to be able to end up having the models have any economic utility at the end of the day.
Alessio Fanelli: I was going to say, Jordan, another way to think about it, just in terms of open source and not as similar yet to the AI world where some countries, and even China in a way, were maybe our place is not to be at the cutting edge of this. It’s to actually have very massive manufacturing in NAND or not as cutting edge production.
I think open source is going to go in a similar way, where open source is going to be great at doing models in the 7, 15, 70-billion-parameters-range; and they’re going to be great models. They’re going to be very good for a lot of applications, but is AGI going to come from a few open-source people working on a model? I find that unlikely.
I think you’ll see maybe more concentration in the new year of, okay, let’s not actually worry about getting AGI here. Let’s just focus on getting a great model to do code generation, to do summarization, to do all these smaller tasks.

There’s No Such Thing as a Free Model
Jordan Schneider: Well, what is the rationale for a Mistral or a Meta to spend, I don’t know, a hundred billion dollars training something and then just put it out for free? Does that make sense going forward? Or has the thing underpinning step-change increases in open source ultimately going to be cannibalized by capitalism?
Alessio Fanelli: Meta burns a lot more money than VR and AR, and they don’t get a lot out of it. I think the ROI on getting LLaMA was probably much higher, especially in terms of brand. I would say that helped them.
There’s obviously the good old VC-subsidized lifestyle, that in the United States we first had with ride-sharing and food delivery, where everything was free. I think now the same thing is happening with AI.
We have a lot of money flowing into these companies to train a model, do fine-tunes, offer very cheap AI imprints.
At some point, you got to make money. There’s not an endless amount of it.
But I think today, as you said, you need talent to do these things too. To get talent, you need to be able to attract it, to know that they’re going to do good work.
If you have a lot of money and you have a lot of GPUs, you can go to the best people and say, “Hey, why would you go work at a company that really cannot give you the infrastructure you need to do the work you need to do? Why don’t you work at Meta? Why don’t you work at Together AI?” You can work at Mistral or any of these companies.
So that’s another angle. It’s almost like the winners keep on winning. It’s like, okay, you’re already ahead because you have more GPUs. Now, you also got the best people. And because more people use you, you get more data. And it’s kind of like a self-fulfilling prophecy in a way.
So I think you’ll see more of that this year because LLaMA 3 is going to come out at some point. I’m sure Mistral is working on something else. OpenAI should release GPT-5, I think Sam said, “soon,” which I don’t know what that means in his mind. But he said, “You cannot out-accelerate me.” So it must be in the short term.
So yeah, there’s a lot coming up there.
Shawn Wang: There is a little bit of co-opting by capitalism, as you put it. Mistral only put out their 7B and 8x7B models, but their Mistral Medium model is effectively closed source, just like OpenAI’s.
In a way, you can start to see the open-source models as free-tier marketing for the closed-source versions of those open-source models.
If this Mistral playbook is what’s going on for some of the other companies as well, the perplexity ones.
There is some amount of that, which is open source can be a recruiting tool, which it is for Meta, or it can be marketing, which it is for Mistral. And there is some incentive to continue putting things out in open source, but it will obviously become increasingly competitive as the cost of these things goes up.
Jordan Schneider: One of the very dramatic things that my eyes were opened to at NeurIPS was that it’s one thing to see the charts about the nationality of researchers, and it’s another thing to be like, “Oh, man, everyone’s speaking Mandarin here, that’s cool.”
And if by 2025/2026, Huawei hasn’t gotten its act together and there just aren’t a lot of top-of-the-line AI accelerators for you to play with if you work at Baidu or Tencent, then there’s a relative trade-off.
Staying in the US versus taking a trip back to China and joining some startup that’s raised $500 million or whatever, ends up being another factor where the top engineers really end up wanting to spend their professional careers.
Open-Source Models & Chinese Labs
Shawn Wang: There is some draw. Yi, Qwen-VL/Alibaba, and DeepSeek all are very well-performing, respectable Chinese labs effectively that have secured their GPUs and have secured their reputation as research destinations. I would consider all of them on par with the major US ones.
Jordan Schneider: Let’s talk about those labs and those models. I’ve played around a fair amount with them and have come away just impressed with the performance. Any broader takes on what you’re seeing out of these companies?
Shawn Wang: DeepSeek is surprisingly good. All of the three that I mentioned are the leading ones. There are other attempts that are not as prominent, like Zhipu and all that. But I would say each of them have their own claim as to open-source models that have stood the test of time, at least in this very short AI cycle that everyone else outside of China is still using.
Usually, in the olden days, the pitch for Chinese models would be, “It does Chinese and English.” And then that would be the main source of differentiation.
But now, they’re just standing alone as really good coding models, really good general language models, really good bases for fine tuning. And I think that’s great.
Jordan Schneider: What’s interesting is you’ve seen a similar dynamic where the established firms have struggled relative to the startups where we had a Google was sitting on their hands for a while, and the same thing with Baidu of just not quite getting to where the independent labs were.
Sam: It’s interesting that Baidu seems to be the Google of China in many ways. I know they hate the Google-China comparison, but even Baidu’s AI launch was also uninspired. They announced ERNIE 4.0, and they were like, “Trust us. It’s better than everyone else.” And no one’s able to verify that.
OpenAI’s Secret Sauce?
Jordan Schneider: Yeah, it’s been an interesting ride for them, betting the house on this, only to be upstaged by a handful of startups that have raised like a hundred million dollars.
I want to come back to what makes OpenAI so special. You guys alluded to Anthropic seemingly not being able to capture the magic.
What from an organizational design perspective has really allowed them to pop relative to the other labs you guys think?
Alessio Fanelli: It’s always hard to say from the outside because they’re so secretive. Like Shawn Wang and I were at a hackathon at OpenAI maybe a year and a half ago, and they would host an event in their office. I think today you need DHS and security clearance to get into the OpenAI office. It’s hard to get a glimpse today into how they work.
Roon, who’s famous on Twitter, had this tweet saying all the people at OpenAI that make eye contact started working here in the last six months. The type of people that work in the company have changed.

I would say they’ve been early to the space, in relative terms. OpenAI is now, I would say, five maybe six years old, something like that. A lot of the labs and other new companies that start today that just want to do what they do, they cannot get equally great talent because a lot of the people that were great — Ilia and Karpathy and folks like that — are already there. They are passionate about the mission, and they’re already there.
Going back to the talent loop. It’s like, “Oh, I want to go work with Andrej Karpathy. I should go work at OpenAI.” “I want to go work with Sam Altman. I should go work at OpenAI.” That has been really, really helpful.
The other thing, they’ve done a lot more work trying to draw people in that are not researchers with some of their product launches. I actually don’t think they’re really great at product on an absolute scale compared to product companies. The GPTs and the plug-in store, they’re kind of half-baked.
But it inspires people that don’t just want to be limited to research to go there. That’s what then helps them capture more of the broader mindshare of product engineers and AI engineers. And they’re more in touch with the OpenAI brand because they get to play with it.
Also, for example, with Claude — I don’t think many people use Claude, but I use it. I use Claude API, but I don’t really go on the Claude Chat. Like there’s really not — it’s just really a simple text box. It makes that it is hard for exploration.
I would say that’s a lot of it. One of my friends left OpenAI recently. He was like a software engineer. He said Sam Altman called him personally and he was a fan of his work.
I don’t think in a lot of companies, you have the CEO of — probably the most important AI company in the world — call you on a Saturday, as an individual contributor saying, “Oh, I really appreciated your work and it’s sad to see you go.” That doesn’t happen often.
That kind of gives you a glimpse into the culture. If you look at Greg Brockman on Twitter — he’s just like an hardcore engineer — he’s not somebody that is just saying buzzwords and whatnot, and that attracts that kind of people.
How they got to the best results with GPT-4 — I don’t think it’s some secret scientific breakthrough. I think it’s more like sound engineering and a lot of it compounding together.
That’s what the other labs need to catch up on. They probably have similar PhD-level talent, but they might not have the same type of talent to get the infrastructure and the product around that.
Shawn Wang: There have been a few comments from Sam over the years that I do keep in mind whenever thinking about the building of OpenAI. He actually had a blog post maybe about two months ago called, “What I Wish Someone Had Told Me,” which is probably the closest you’ll ever get to an honest, direct reflection from Sam on how he thinks about building OpenAI.
A lot of it is fighting bureaucracy, spending time on recruiting, focusing on outcomes and not process.
For me, the more interesting reflection for Sam on ChatGPT was that he realized that you cannot just be a research-only company. You have to be sort of a full-stack research and product company. Now with, his venture into CHIPS, which he has strenuously denied commenting on, he’s going even more full stack than most people consider full stack.
That seems to be working quite a bit in AI — not being too narrow in your domain and being general in terms of the entire stack, thinking in first principles and what you need to happen, then hiring the people to get that going. It seems to be working for them really well.
Jordan Schneider: I felt a little bad for Sam. Those CHIPS Act applications have closed. I don’t think he’ll be able to get in on that gravy train. But it was funny seeing him talk, being on the one hand, “Yeah, I want to raise $7 trillion,” and “Chat with Raimondo about it,” just to get her take.
Engineering Talent at the Frontier
Jordan Schneider: Alessio, I want to come back to one of the things you said about this breakdown between having these research researchers and the engineers who are more on the system side doing the actual implementation.
There’s a long tradition in these lab-type organizations. The culture you want to create should be welcoming and exciting enough for researchers to give up academic careers without being all about production.
We’ve heard lots of stories — probably personally as well as reported in the news — about the challenges DeepMind has had in changing modes from “we’re just researching and doing stuff we think is cool” to Sundar saying, “Come on, I’m under the gun here. Everyone wants to fire me. Let’s ship some stuff already.”
Would you expand on the tension in these these organizations? They have to walk and chew gum at the same time.
Alessio Fanelli: I see a lot of this as what we do at Decibel. We invest in early-stage software infrastructure. Usually we’re working with the founders to build companies. I’ve seen a lot about how the talent evolves at different stages of it. I just mentioned this with OpenAI. It is not that old. It’s only five, six years old.
If you think about Google, you have a lot of talent depth. As with tech depth in code, talent is similar.
You’re trying to reorganize yourself in a new area. You have a lot of people already there. They might not be ready for what’s next.
If you think about AI five years ago, AlphaGo was the pinnacle of AI. It’s a research project. You’re playing Go against a person. But they’re bringing the computers to the place. They’re all sitting there running the algorithm in front of them. It’s not a product.
Now, all of a sudden, it’s like, “Oh, OpenAI has 100 million users, and we need to build Bard and Gemini to compete with them.” That’s a completely different ballpark to be in.
Some people might not want to do it. They might not be built for it. But then again, they’re your most senior people because they’ve been there this whole time, spearheading DeepMind and building their organization. It takes a bit of time to recalibrate that.
We see that in definitely a lot of our founders. They are people who were previously at large companies and felt like the company could not move themselves in a way that is going to be on track with the new technology wave. They end up starting new companies.
I think what has maybe stopped more of that from happening today is the companies are still doing well, especially OpenAI. OpenAI is an amazing business. I don’t really see a lot of founders leaving OpenAI to start something new because I think the consensus within the company is that they are by far the best. They have, by far, the best model, by far, the best access to capital and GPUs, and they have the best people.
There’s not leaving OpenAI and saying, “I’m going to start a company and dethrone them.” It’s kind of crazy.
You see maybe more of that in vertical applications — where people say OpenAI wants to be.
I use this analogy of synchronous versus asynchronous AI. OpenAI is very synchronous. You go on ChatGPT and it’s one-on-one. You use their chat completion API. You do one-on-one. And then there’s the whole asynchronous part, which is AI agents, copilots that work for you in the background. Things like that. That is not really in the OpenAI DNA so far in product.
You see a company — people leaving to start those kinds of companies — but outside of that it’s hard to convince founders to leave. We tried. We had some ideas that we wanted people to leave those companies and start and it’s really hard to get them out of it.
But I’m curious to see how OpenAI in the next two, three, four years changes. Because it will change by nature of the work that they’re doing. And maybe more OpenAI founders will pop up.
Jordan Schneider: Part of the reason you keep your brilliant PhD’s happy is to be the first to find and exploit architectural advancements.
In part 2, we get into:
OpenAI's secretive Q* project and what it means for GPT-5.
How a revolution in AI search could transform algorithmic problem-solving and shape how companies fast follow.
How AI diffusion could unlock massive productivity growth in GPU “rich” and “poor” nations alike in the coming decades.
Why the CCP’s biggest obstacle in AI development is… probably the CCP.
Chinese labs’ innovation on Mixture of Experts models, and how they’re outpacing Western labs in this domain.
Why coding will still be worth doing despite the rise of prompt engineering.

{kind=link}